Introduction & Related Work
2024년 NeurIPS에 발표된 “One-Step Effective Diffusion Network for Real-World Image Super-Resolution” (OSEDiff)를 리뷰해보려 한다. 이 논문은 실세계 이미지 초해상도(Real-ISR) task를 one step diffusion모델로 해결하려는 논문이다.
기본적으로 최근 super resolution task는 diffusion 모델이 접목되기 시작하면서 perceptual한 퀄리티가 눈에띄게 향상했다. 관련 논문으로는
SUPIR(Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild, 2024 CVPR),
SeeSR(SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution, 2024 CVPR) 등의 논문이 있다.
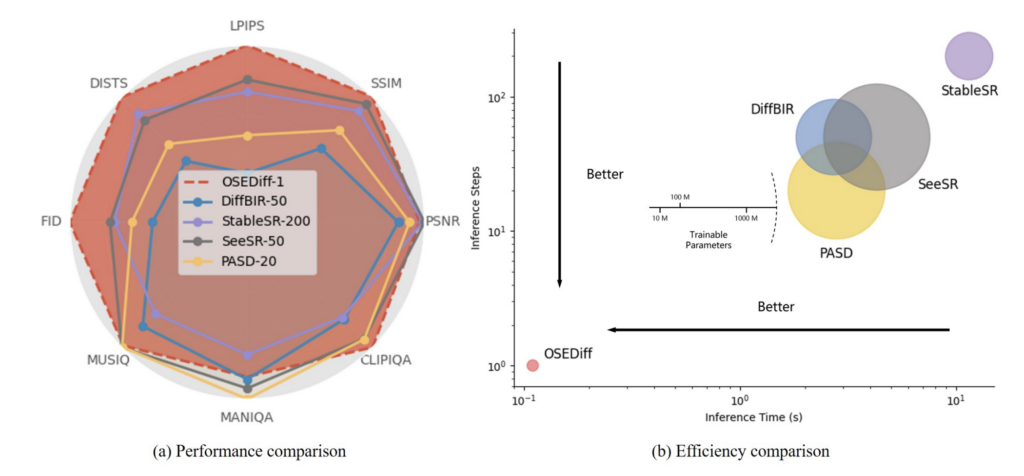
하지만 diffusion 모델의 대표적인 단점인 긴 inference시간은 여전히 한계점이고 이를 해결하기 위해 diffusion모델을 distillation해서 one step으로 만드는것이 이 논문의 메인 목적이다. 사실 사용된 distillation 방법론 자체는 이미 One-step Diffusion with Distribution Matching Distillation (DMD)(2024 CVPR) 에서 제안된 방식과 크게 다르지 않다. 이를 super-resolution task에 맞게, 그리고 latent diffusion model에 맞게 잘 개선한 논문이라고 이해하면 될것 같다. 흥미로운것은 아래 성능표에 나와있듯이 inference time은 엄청나게 줄어드는데 심지어 성능도 좋아진다. 사실 super resolution같은 low level task에서는 diffusion을 여러 스텝 밟으면서 원래 이미지와 점점 다르게 만드는것보다 단 한번의 inference로 이미지를 뽑는게 더 이미지를 망치지 않고 퀄리티도 좋게 만들 수 있을 수 있다는 얘기를 한다.
Methodology
전반적인 학습 pipeline은 아래와 같다.
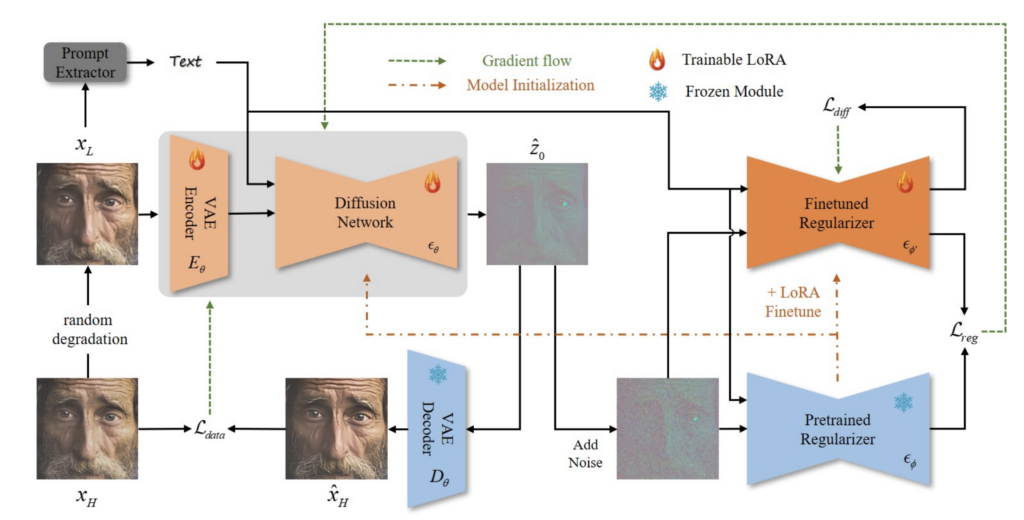
먼저 모델을 구분해보면
- 실제 generator로 사용되는 VAE Encoder, Diffusion Network, VAE Decoder
- pretrained stable diffusion을 그대로 가져온 pretrained regularizer
- pretrained stable diffusion을 가져와서 generated sample에 대해 추가로 학습되는 finetuned regularizer
- text prompt를 뽑는 prompt extractor
이렇게 구분할 수 있다. 그림에도 나와있지만 이중에 VAE Decoder와 Pretraiend Regularizer는 학습을 하지 않고 freeze해서 사용하고 나머지 모델을 LoRA finetuning을 진행한다. prompt extractor는 이미지에서 tag들을 뽑아내는 식으로 사용하고 이것도 학습을 하진 않고 외부 모델을 가져와 사용한다.
regularizer들의 역할을 조금 간단히 설명하고 넘어가면, pretrained regularizer는 stable diffusion이 실제 이미지에 대한 score를 측정하는 역할을 하고 finetuned regularizer는 generator에 의해 생성된 이미지에 대한 score를 측정하는 역할을 한다. 그 두 score를 비슷하게 만듦으로써 generator를 통해 생성되는 이미지가 실제 이미지의 score와 유사하도록 만든것이 목표가 된다. 이제 loss들을 자세히 설명해보고자 한다.
기본적인 loss fcuntion은 아래와 같은 구조에서 시작한다.
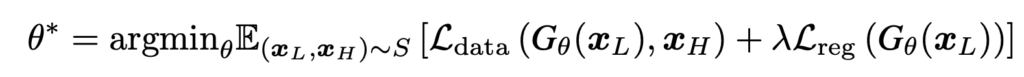
\( x_L \) 과 \(x_H\)는 low quality 이미지와 high quality 이미지고 \(G_\theta \)는 geneartor이다. 그러면 두 데이터 pair를 이용해서 \( L_\text{data}\)를 만들 수 있고 generation된 결과를 가지고 regularizer loss를 만들어 \( L_\text{reg} \)로 학습을 시킬 수 있다. 여기서 \( L_\text{data}\)의 역할은 \( G_\theta (x_L) \) 과 \(x_H\)를 가깝게 만드는 일을 하고 \( L_\text{reg} \)는 generation된 결과가 정말 realistic 해지도록 만드는 일을 한다.
먼저 간단하게 만들수 있는 \( L_\text{data}\) 부터 보면 아래와 같이 만들어 사용한다.
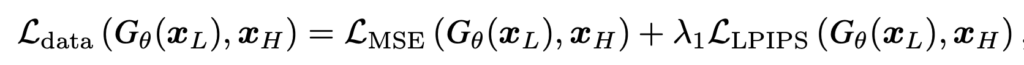
다음으로 \( L_\text{reg} \)를 구하기 위해선 먼저 아래와 같이 KL divergence에서 시작한다.
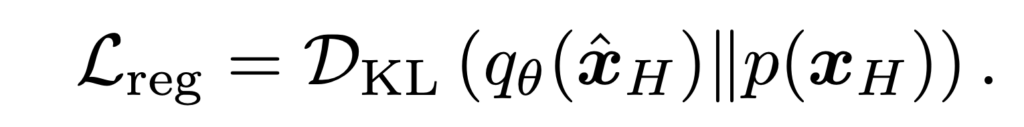
먼저 \(q_\theta(\hat{x}_H)\) 는 generated된 high quality 이미지의 분포가 되고 \(p(x_H)\) 가 실제 high quality의 분포라고 하면 둘이 유사하도록 만드는것이 이상적인 regulizer일 것이다. 당연히 우리가 \( p \) 분포를 정확하게 알 수 없다. 따라서 score based diffusion model에서 하듯이 미분해서 score를 예측하는식으로 바꿔서 loss를 만들어야한다. 따라서 위의 식에서 출발해서 아래와 같이 variational score distillation (VSD) loss 를 제안한다.
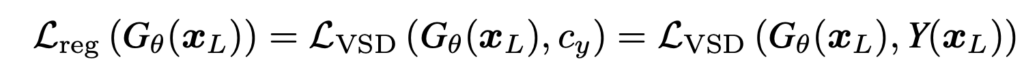
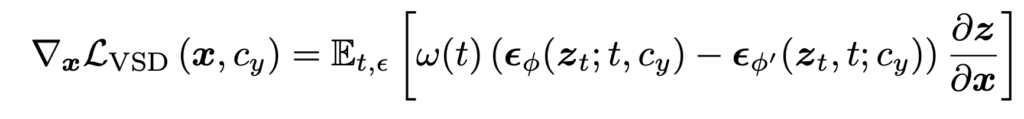
여기서 \( \epsilon_\phi \)는 pretrained diffusion model이 되고 \( \epsilon_{\phi’} \)은 finetuned regularizer가 된다. 각각의 output이 입력이미지에 대한 score가 되는데 그 둘이 유사해지도록 만드는 loss가 된다. 즉, pretraiend stable diffusion이 측정하는 입력 이미지에 대한 score와 finetuned regularizer가 측정하는 이미지에 대한 score를 유사하게 만드는게 목표이다. 여기서 score를 정확하게 예측하기 위해 latent상에서 노이즈를 더해서 \( z_t \)를 만들어서 score를 예측하도록 한다.
finetuned regularizer는 generation된 이미지의 score를 예측하도록 학습이 되어야하기 때문에 아래와 같은 loss로 학습이 된다.

\( \hat{z}_H \)는 generator에서 나온 output latent에 noise \( \epsilon \)를 더한것이고 이를 예측하도록 학습해서 generation된 이미지의 score를 예측하도록 만든다.
학습 자체는 동시에 일어나기 때문에 generator와 regularizer가 학습과정에서 계속 같이 학습이 되게 된다.
마지막으로 위에서 나왔던 VSD loss를 model gradient로 다시 쓰면 아래와 같이 된다. VSD loss가 시작할때 x에 관해 미분하면서 시작하는데(이미지 space에서 시작) 이를 latent space에서 작동하도록 식을 바꾸는데 기본적으로 encoder, decoder가 완벽하게 latent와 이미지를 변환해준다고 가정하기 때문에 크게 달라지는것은 없다.
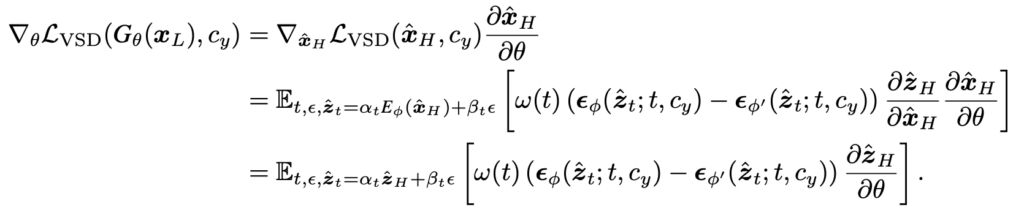
Experiment
기본적으로 onestep 모델임에도 불구하고 stableSR이나 SeeR등이 200step, 50step 한것과 거의 비슷한 성능을 낸다.
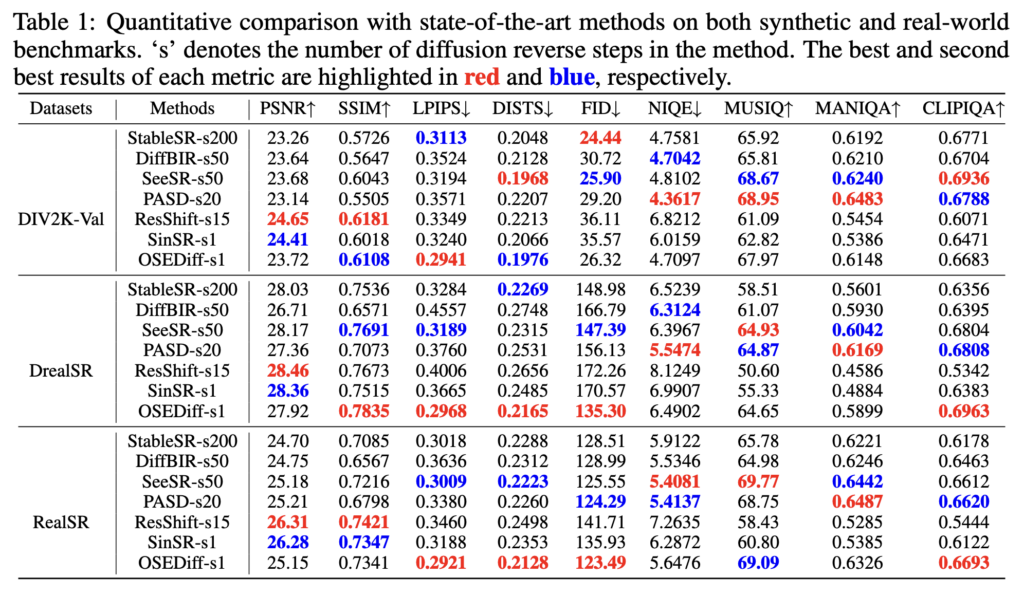
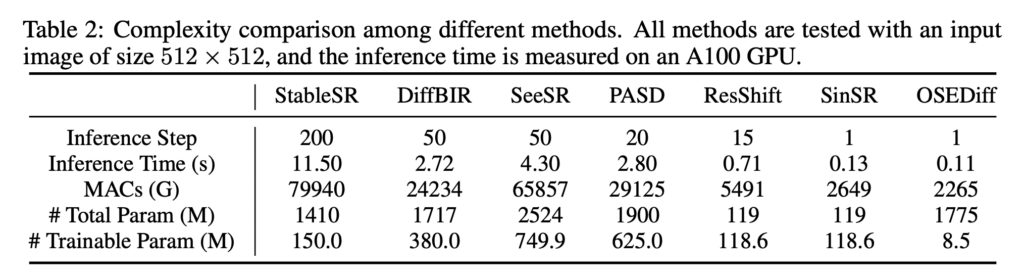
Inference time을 보면 아래와 같이 다른 모델에 비해 압도적으로 빨라지는것을 볼 수 있다. 심지어 학습은 lora 파라미터만 학습시키기 때문에 trainable parameter도 매우 적다.
Qualitative 결과도 매우 훌륭하다.

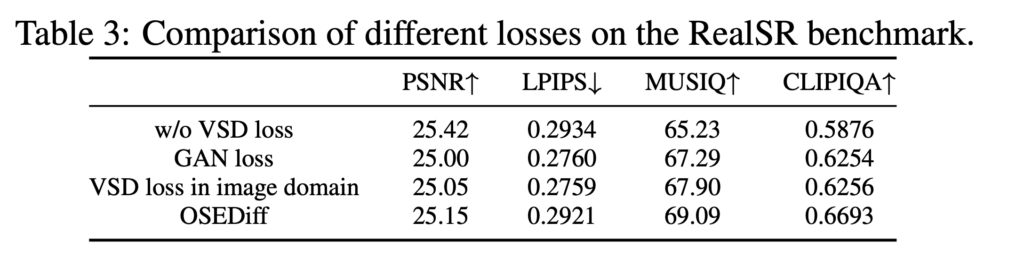
다음은 ablation 인데 첫줄에 VSD loss를 안쓴 결과를 보면 사실 오히려 psnr은 조금 올라가는 것 같은데 다른 이미지 퀄리티 평가 metric들에서 성능이 떨어진다. VSD loss가 stable diffusion이 가지고 있는 natural한 이미지의 분포를 잘 전달해주면서 high quality 이미지와 단순히 regression loss로만 학습할때 생기는 over smooth현상을 해결해주는것으로 보인다. 그 외에도 VSD loss를 latent에서 안쓰고 image domain에서 쓴것과 비교해봐도 latent에서 하는것이 성능이 더 이미지 퀄리티를 높이는것처럼 보인다.
Conclusion & Limitation
일단 one step 모델로 이정도로 성능이 나온다는것이 놀랍다. 심지어 multi step 모델들 보다도 성능이 좋을때가 있는데 pretrained diffusion model의 natural image prior에 대한 정보를 잘 distillation 하도록 잘 설계된 학습방식이라는 생각이 든다.
하지만 여전히 한계점이라고 한다면 위에 그림에는 나오지 않지만 이미지의 작은 부분들은 복원할때 semantic이 붕괴가 되는 현상이 나타난다. 작은 text나 매우 작은 사람 얼굴들이 실제로 복원된 이미지를 확대해보면 붕괴되어 있다. 이는 stable diffusion의 한계점이라고도 생각이 들기도 하고 더 잘 distillation하면 과연 없어질 수도 있는 현상일지 아직 더 연구되어야되는 부분인것 같다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.