
Introduction
2024 뉴립스에 발표된 논문이고 instrucrtion을 기반으로 low-level vision task를 수행하는 논문이다. 이전에 포스트한 instructIR과 비슷한 느낌인데 instructIR에서는 단순 unet으로 image를 바로 뽑아냈다면 이 논문에서는 diffusion을 활용한것이 첫번째 차이점이고, instrcutIR에서는 instruction이 거의 classification용으로만 거의 쓰였는데 이 논문에서는 task중에 object removal같은 editing task가 있어서 이를 위해 instruction에서 단순 task정보 이외에도 문맥의 정보를 디테일하게 얻어야한다는 점이 두번째 차이이다. 추가로 diffusion에서 잘 안되는 이미지 디테일 보존을 frequency guiding 같은 technique으로 극복하려 한 것이 contribution인 것 같다. instructIR에 대한 포스트는 다음 링크를 참조 (https://doinghun.com/instructir-high-quality-image-restoration-following-human-instructions-2024-cvpr/)
논문에서 진행한 low-level vision task는 아래와 같다
총 7개의 task이고 이를 instruction 기반으로 수행하도록 학습시킨다.
이 논문도 마찬가지로 대부분의 instruction 기반 image editing을 할 때의 문제가 instruction과 image가 pair로 같이 있는 dataset이 없다는 것이다. 그리고 대부분의 해법도 비슷하게 GPT같은 생성모델을 쓰는것이다. 이 논문도 마찬가지로 GPT4를 사용해 instruction을 얻어낸다. 이외 디테일한 데이터셋 생성 방법은 이후 Data Curation 섹션에서 소개한다.
Data Curation
일단 기존 dataset들로부터 source image들을 얻는다. 그 이미지들에 손상을 가하거나 inpainting으로 새로운 이미지를 만들어 내서 input-output 에 해당하는 pair 데이터셋을 만든다. (사실상 appendix의 detail을 보면, restoration용 dataset들은 만들어져 있는 데이터셋 그대로 사용하고, colorization 같은 경우에는 기존 image dataset에서 grayscale로 이미지를 만들어내서 pair로 만들고 object removal도 annotation이 layer별로 있는 데이터셋을 이용해서 만든다. 따라서 기존 데이터셋을 거의 그대로 이용하는 수준이고 새로 생성을 하거나 하진 않는다. 덕분에 훨씬 realistic한 pair가 생기는것 같다)
이제 이 이미지 쌍에 추가될 instruction을 만들어야 하는데 이때는 GPT-4를 사용한다. 이때 instruction에는 두가지 정보가 있도록 한다. 1. task-specific, 2. general instruction. 예를 들어 task-specific prompt는 “안개를 제거하고 visibility를 좋게 해줘” 라는 어떤 작업을 수행해야하는지에 대한 정보를 제공하고 general instruction은 이미지에 대한 semantic한 정보를 가지고 있는 instruction을 말한다. 이러한 insturction prompt를 \( P_{instruction} \) 으로 정한다.
Methodology
Diffusion Model
이후에 sampling을 하는 과정에서는 high-frequency guiding이라는 기법이 들어가는데 Diffusion Model 학습자체에서는 특별하게 이 논문에서 제안한 방법은 없고 stable diffusion에서 training 하는 방법 그대로 한다.
VLM-based Auxiliary Prompt Module
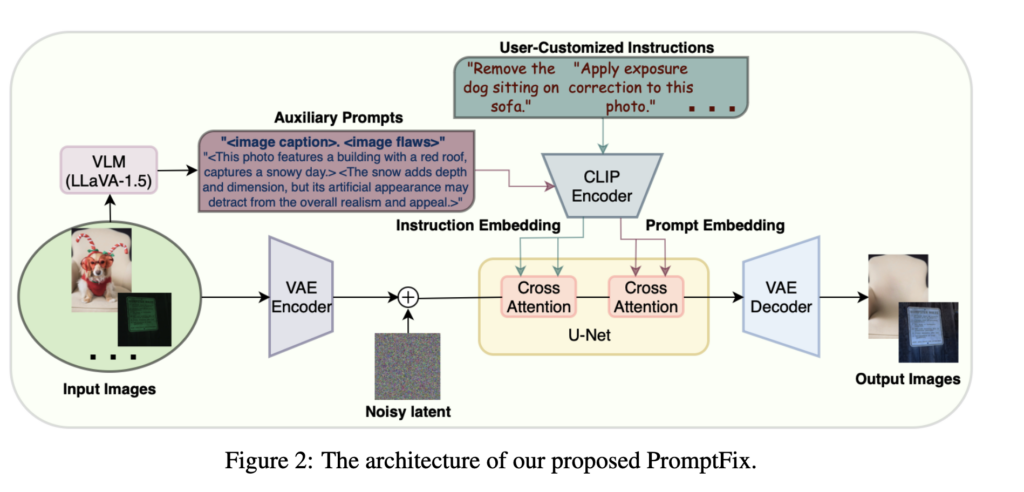
Auxiliary Prompt 대해 설명하기 전에 먼저 위의 Figure 2를 보면 전체적인 overview가 나와있다. 일단 이미지를 VLM을 통과시켜 Auxiliary prompt를 얻어내고 clip encoder에 넣어서 prompt embedding을 얻어낸다. 마찬가지로 user가 직접 입력한 instruction도 clip encoder에 넣어서 instruction embedding을 얻어낸다. 이를 diffusion 모델에 cross attention에 넣어서 이미지를 guiding한다. user instruction은 사용자가 직접 입력하는 것이기 때문에 따로 얻을 필요는 없고(학습 할때는 데이터셋에 포함된 instruction임) auxiliary prompt는 VLM(Vision-Language Model)을 통해 얻어내야하는 prompt이다. 개인적인 생각으로 auxiliary prompt를 쓰는 이유는 user instruction이 모호하거나 정보가 부족할 수 있기 때문인것 같다. 매번 유저가 이미지에 대해서 디테일한 설명을 하지는 않고 대부분 추상적이거나 간단하게 명령어를 쓸 것이기 때문에 instruction이 semantic한 정보나 task관련 정보가 부족할 수가 있다. 따라서 user instruction을 보조해줄 수 있는 auxiliary prompt를 degraded image로부터 직접 얻어내서 이를 보조하기 위해 사용하려는 것 같다. 이를 얻어내기 위한 방법이 아래에 소개된다.
이 논문에서는 pretrained LLaVA 모델을 써서 auxiliary prompt 를 얻는다. 이때 auxiliary prompt란 task-specific한 정보도 있고 general instruction에 대한 정보도 들어있는 prompt이어야 한다. 어떻게 얻는지 아래 식을 통해 보자. 먼저 pretrained LLaVA모델을 \( V \), 파라미터를 \( w \) 라고 하고, LLaVA의 visual encoding model이 \( \phi \), input으로 들어가는 degraded image가 \( I \), 그리고 textual query가 \( Q \), 그리고 tokenized language embedding이 \(\tau(Q) \) 가 되어 최종적으로 textual response \( R \)은 아래와 같은 식으로 표현된다.
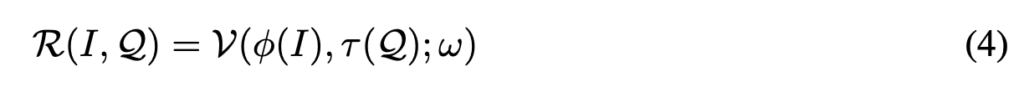
그런데 LLaVA 같은 모델도 대부분 clean한 이미지로만 학습돼었지 손상된 이미지에 대해서는 학습이 잘 되어있지 않고, 따라서 이 논문에서는 text query를 이에 맞게 나눈다. 위에서 언급했듯이 general한 정보를 가지는 \( Q_{semantic} \) 과 task specific한 정보를 가지는 \( Q_{defect} \) 를 각각 만들어서 LLaVA에 각각 넣어서 두 text response를 얻은후 합쳐서 최종 prompt 인 \( P_{auxiliary} \)를 얻어내는 것이다. 위의 Figure2의 Auxiliary Prompt에서 <image caption> <image flaws> 라고 써있는 부분이 각각 \( Q_{semantic} \) , \( Q_{defect} \) 가 된다. appendix에 각각의 디테일한 prompt가 나와있고 아래와 같다.

최종 결과를 얻는 방식을 식으로 표현하면 아래와 같다.
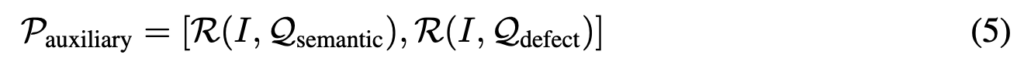
이 prompt \( P_{auxiliary} \)와 user instruction에 의해 얻어진 \( P_{instruction} \) 을 각각 clip에 넣어 임베딩을 얻고 각각 cross attention의 key, value로 사용을 해서 를 이제 diffusion 모델에서 cross-attention layer에 임베딩을 해서 최종적으로 원하는 이미지를 얻도록 한다. 아래 그림은 VLM을 통해 얻어낸 auxiliary prompt를 보여준다. 파란색이 \( Q_{semantic} \), 노란색이 \( Q_{defect} \)에 의해 생긴 prompt이다.

High-frequency Guidance Sampling
기본적으로 image restoration와 editing에서는 높은 정확도로 원래 이미지의 semantics를 유지하는 것을 요구한다. 하지만 stable diffusion 특성상 VAE를 사용하고 어쩔 수 없이 image detail의 손상이 간다. 예를 들자면 아래와 같은 이미지들이다. 기존의 diffusion을 이용한 이미지 editing 결과는 아래처럼 글씨같은 디테일이 많이 뭉개진다. 이를 막고자 하는 것이 high-frequency guiding이다. 아래 그림에서 HGS(High frequency Guidance Sampling) 방법이 있고 없고가 이미지 디테일 복구에 큰 영향을 끼치는 것을 알 수 있다.

먼저 VAE decoder에 VAE encoder에서 오는 skip connection을 만든다. 이를 중간 중간 feature map에 섞어서 원래 이미지의 정보가 최대한 넘어오도록 하는것이다. 이때 중간에 LoRA convolution을 이용해서 feature map merging을 하는데 네트워크 자체가 lightweight해서 fine-tuning을 많이 안해도 금방 학습이 된다고 한다.
또한 diffusion에서 sampling을 하는 과정에서도 high frequency 정보가 잘 유지도도록 하는 technique을 추가한다. 주파수 도메인에서 고주파 성분만 필터링을 하는 high pass filtering \( F() \)이랑 edge detection에 쓰이는 Sobel edge detection operator \( S() \) 를 이용해서 원본 이미지의 high frequency 정보가 sampling하면서 계속 잘 유지될 수 있도록 하는것이다. 식으로 보면 아래와 같다.
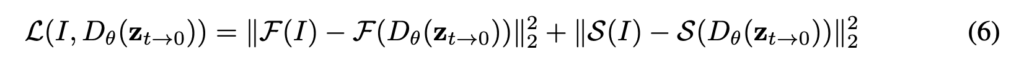
이걸 sampling을 하면서 중간에 계속 decoder를 업데이트 하면서 high frequency정보를 잘 유지할수 있도록 VAE의 decoder가 학습이 된다. sampling 알고리즘은 아래와 같다.

알고리즘에서 파란색으로 되어있는 부분이 high-frequency guidance를 위해 추가된 부분이고 검정색은 원래 stable diffusion에서의 sampling의 알고리즘이다. sampling할때마다 노이즈를 예측하고 이를 이용해 \( z_{t-1} \)을 예측하고 이를 반복하는게 원래 stable diffusion인데 여기서 \( z_{t->0} \)를 추가로 예측하게 한뒤 이를 decoder \( D_\theta \)를 이용해 복원한 이미지가 원래 이미지인 \( I \)와 high frqeuency에서 비슷해지도록 위의 식 6을 써서 decoder를 업데이트 하는거이다. \( z_{t->0} \)를 구하는 방법은 아래 식을 이용한다.
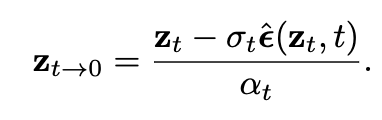
위 식이 하는일은 결국 t step에서 예측한 노이즈를 이용해 바로 \( z_0 \) 예측하는 과정이다. 따라서 당연히 t가 클수록 정확하지 않은 이미지가 나올 것이기 때문에 그에 대한 weight을 반영해주기 위해서 위 알고리즘에서 마지막 loss앞에 \( e^{-\lambda t} \)를 추가해 t가 클때는 loss가 적게 들어가고 sampling이 진행되고 t가 작아짐에 따라 \( D_\theta (z_{t->0}) \)이 더 정확한 이미지가 나오게 되므로 더 큰 비율로 loss가 적용이 된다. 이렇게 해서 새로 생성된 이미지가 입력 이미지와 high frequency에서 유사한 결과를 가지도록 guiding을 한다.
Experiment
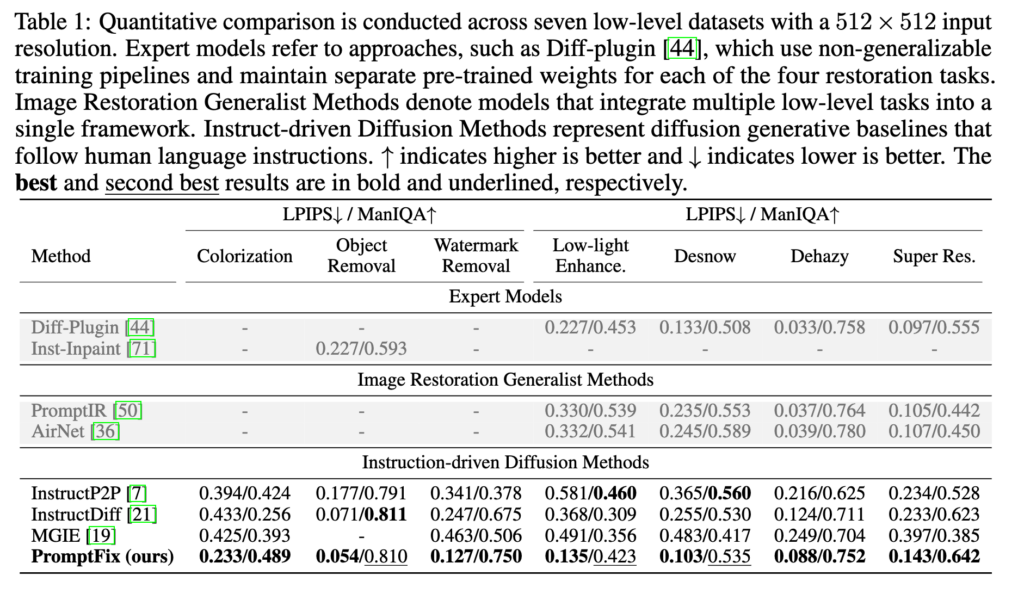
다른 instruction 기반 이미지 editing / restoration 방법들이랑 비교할 때 훨씬 좋은 quantitative 결과를 보인다. 사실 talbe에 회색을 쳐져있는 diff-plugin, PromptIR, AirNet 등은 특정 task로 학습된 all-in-one image restoration 기법들인데 instruction으로 작동하는건 아니고 학습된 task에만 알아서 작동하는 식인데 수치상으로 보면 얘네가 더 좋긴 하다. 하지만 이 방법들은 instruction으로 task를 조정할 수 없기 때문에 object removal, watermark removal등의 task를 수행하는 것은 불가능하다. 그런점에서 PromptFix가 Flexible하면서도 다양한 task에 좋은 성능을 거두고 있다는 점이 의의가 있는것 같다.
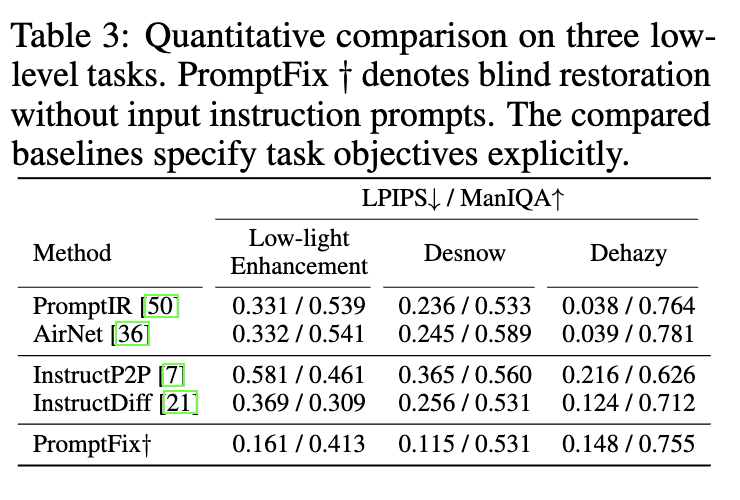
또한 이 논문에서 제안한 방법에 따르면 VLM이 auxiliary prompt를 생성해주는데 이 prompt만 사용해도 사실 이미지 변환이 가능하다. 따라서 user-instruct 없이 이 auxiliray prompt만 이용해서 생성했을 때의 결과가 아래 테이블3이다. 위의 table1과 비교하면 성능이 약간씩 떨어졌지만 그래도 꽤나 성능이 잘 나오고 visual적인 차이도 크지 았다고 한다.
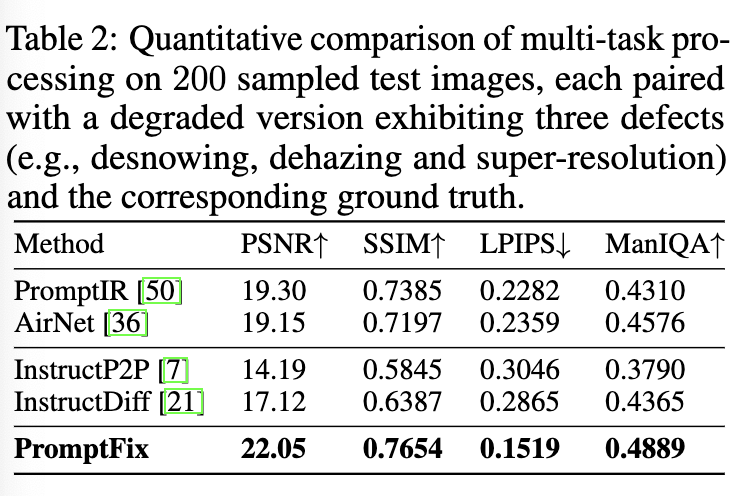
또한 아래는 multi-task에 대한 결과이다. 이 논문에서 PromptFix를 학습시킬 때는 이미지 한장당 하나의 degradation만 가해서 학습을 시킨다. 그런데 실제로는 하나의 이미지에 여러 degradation이 혼합된 경우가 존재한다 (eg. 어두운 상황에서 안개가 끼고 눈이오는 등). 따라서 이에 대한 evaluation을 하기 위해 200장의 validation 이미지를 구성하고 거기에 3가지 degradation이 같이 존재하도록 만들어 성능을 측정한결과가 아래 table이다. 다른 method들에 비해 훨씬 좋긴 하지만 사실 수치 자체가 그렇게 높지 않은걸 봐서는 엄청 잘 되는건 아닌것 같다. 그래도 그 아래 visual 결과는 매우 좋아보이긴 한다.

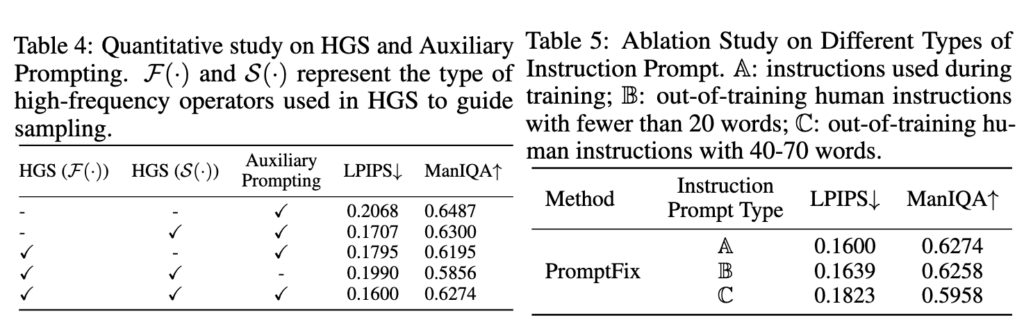
마지막으로 ablation실험으로 두가지 정도 진행을 하는데 아래 테이블4, 5에 나와있다. 먼저 Table4를 보면 high frequency sampling이랑 auxiliary prompting을 추가했을때의 성능 gain이고 보면 확실히 HGS와 Auxiliary prompting을 같이 썼을때 성능이 확확 좋아지는 것 같다. 그리고 Table 5는 trianing에 사용된 생성된 instruction prompt대신에 사람이 직접 instruction prompt를 작성해서 그에 대한 결과를 측정한것이다. 사람이 instruction은 20단어 이하로 썼을때는 성능이 차이가 거의 없었고 instruction이 길어지면 성능이 떨어지는데 사실 low-level vision task에서 instruction을 길게 쓸 이유가 없기 때문에 충분히 out-of-distribution의 instruction에 대해 robust하게 작동한다고 볼 수 있다.
Conclusion
diffusion으로 high quality로 이미지 restoration과 editing을 성공한것이 꽤나 의미가 있는것같다. 항상 diffusion으로 이미지 editing을 하면 문제가 text가 뭉개지거나 detail이 날아가는거였는데 high frequency sampling 방법이 꽤나 유의미한 것 같다.
몇가지 의문점은
- high-frequency guiding이 최종 생성된 이미지와 입력 이미지간의 high frequency를 유사하게 하자는건데 object removal 같은 경우에는 사실 object가 날아가는 부분은 high frequency 정보도 필요가 없는데 HGS를 적용하면 오히려 안좋지 않나? 지울 물체만 빼고 high-frequency guiding을 해야 할텐데 그런 technique은 없는것 같아서 그 부분이 의문이다.
2. 학습한 데이터 이외의 새로운 이미지에 대해서 얼마나 robust하게 작동하는지가 궁금하다.
3. 이 논문도 결국엔 학습된 task밖에 수행하지 못한다. 즉 이 모델로 denoising, deblurring을 하지는 못한다.(학습되지 않았기 때문에). 그러면 사실 instruction에 대해 정말 자유롭게 low-level vision task가 수행된다고는 아직 말할 수 없는것 같다. 학습되지 않았어도 text에서 semantic하게 degradation정보를 알아내서 그에 대한 restoration을 정말 모든 task에 대해서 할 수 있어야 이 instruction이 궁극적으로 의미가 있는것 같은데 그것까진 아직 안되는것 같다. VLM이나 CLIP이 이 degradation에 대해서 얼마나 정보를 가지고 있는가가 중요할것 같다. 이미지만 보고도 흔들림, 노이즈, 눈, 비, 그림자 등등 다양한 degradation정보를 이미 VLM이 알고 있다면 문제가 쉬울 것 같은데 얼마나 잘 알고 있을지 테스트를 해봐야할 것 같다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.