Introduction
이번에 리뷰할 논문은 2022 CVPR에 나왔던 All-In-One Image Restoration for Unknown Corruption, 줄여서 AIRNet이다.
제목 그대로 다양한 이미지 손상에 대해서 네트워크 하나로 한번에 복원하는 것을 목적으로 한다.
대부분의 이미지 복원 분야에서는 네트워크 하나를 하나의 task로만 학습시켜서 사용한다. 예를들어 denoising 목적으로 네트워크를 학습시키면 그 네트워크는 학습한 noise만 잘 제거하고 다른 타입의 노이즈는 제거하지 못한다. 이 논문에서는 아래 그림처럼 네트워크 하나로 denoising, deraining, dehazing 등등 다양한 이미지 복원 task를 한번에 하는 것을 목적으로 한다.
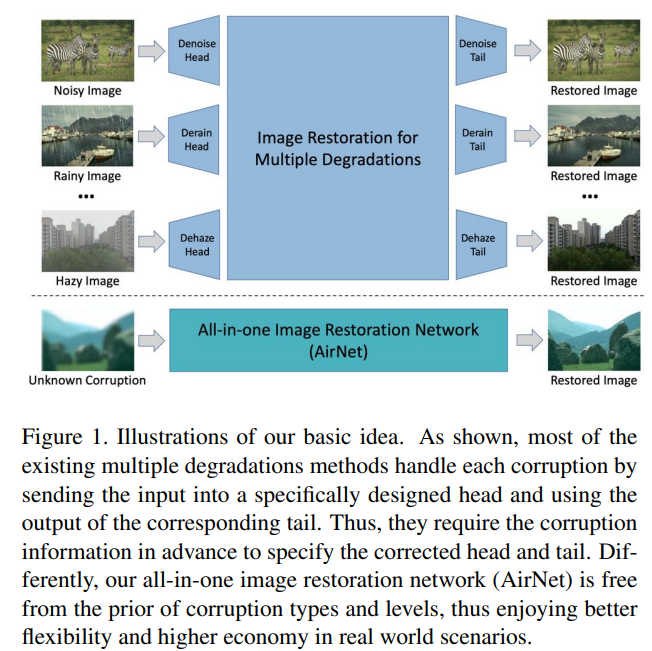
기존에도 이미지 복원 분야를 multi-task learning 방식으로 해결하려는 시도는 있었다. degradation에 대한 정보를 바탕으로 task-specific한 encoder와 decoder를 사용하는 등의 방법이 있는데 기본적으로 degradation에 대한 정보를 알고 있어야 한다는 점 때문에 한계가 있었다. 여기서는 그러한 degradation에 대한 정보가 전혀 없이도 말그대로 unknwon corruption에 대한 이미지 복원을 할 수 있도록 만들었다.
Related work
Image Restoration for Single Degradation : DnCNN부터 시작해서 많은 Restoration 모델들이 있지만 대부분 unseen degradation에 대해서는 잘 작동하지 않는다. 이에 대해 다른 degradation에 대해서도 강건한 그런 모델들이 나오기도 했지만 여전히 다른 task에 대해서는 다른 model을 학습시켜야되기 때문에 all-in-one solution은 없었다.
Image Restoration for Multiple Degradations :
이 논문과 비슷한 work들로
“All in One Bad Weather Removal using Architectural Search (2020 CVPR)”
“Pre-Trained Image Processing Transformer (2021 CVPR)”
등이 있는데 multi encoder나 multi tails를 쓰는 방식이다. 하지만 multi encoder나 multi tails를 쓰는 방식은 기본적으로 degradation에 대한 정보가 있어야 특정 encdoer나 특정 tail로 보내줄 수 있기 때문에 완전한 unknown corruption을 다루는데 한계가 있다.
가장 유사한 work으로는
” A General Decoupled Learning Framework for Parameterized Image Operators. (2021 TPAMI)”
가 있는데 이 또한 input degradation에 대한 prior가 주어져야 하므로 완전한 unknown corruption은 다룰 수 없다.
Contrastive Learning
unsupervised representation learning 방법에서 굉장히 많이 쓰이는 학습 방식이다. positive pair 이미지들 끼리는 거리가 가깝게, negative pair 이미지들 끼리는 거리를 멀게 만드는 방식인데 이를 이용해 이미지 복원에 활용한다.
Method
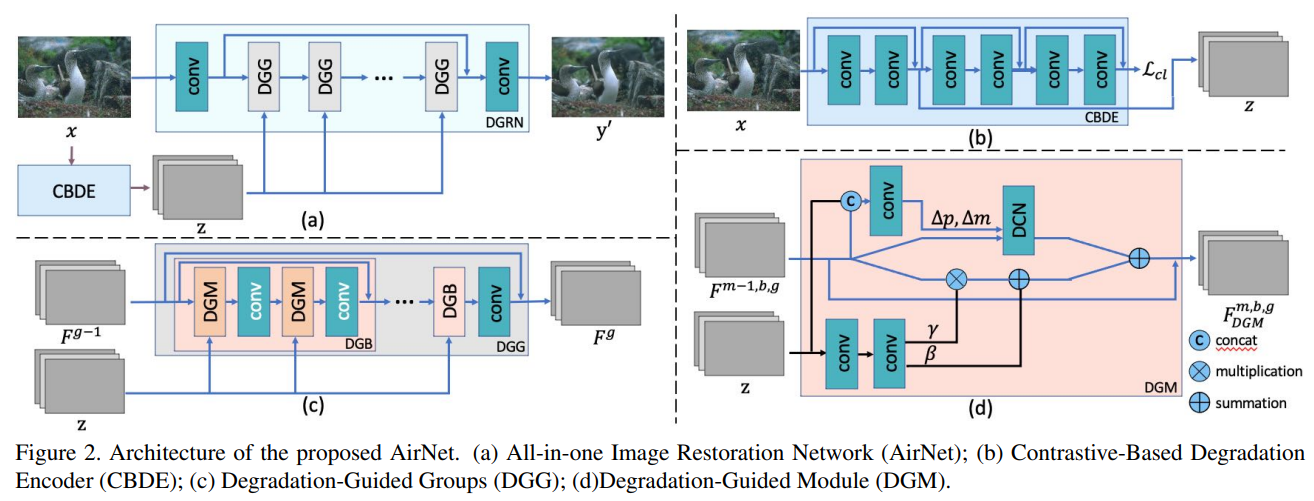
기본적으로 contrastive learning을 base로 해서 이미지를 z로 encoding하는 CBDE (Contrastive-Based Degradation Encoder) 모듈이 있고 z와 input 이미지를 받아 clean 이미지로 복원하는 DGRN (Degradation Guided Restoration Network)이 있다. DGRN은 또 그 안에 DGG (Degradation-Guieded Groups) block들이 존재하고 그 block들은 DGM (Degradation-Guided Module)과 convolution으로 이루어져 있다. 이에 대한 overview figure는 아래와 같다.
먼저 loss function을 살펴보면 네트워크를 통해 복원한 이미지와 clean 이미지 간의 L1 loss를 측정하는 Lrec가 있고 contrastive-based 방식을 적용하는 Lcl이 있다. total loss는 둘을 더해서 만들어진다. 먼저 total loss와 Lrec 식은 아래와 같다.
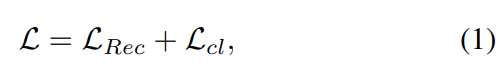
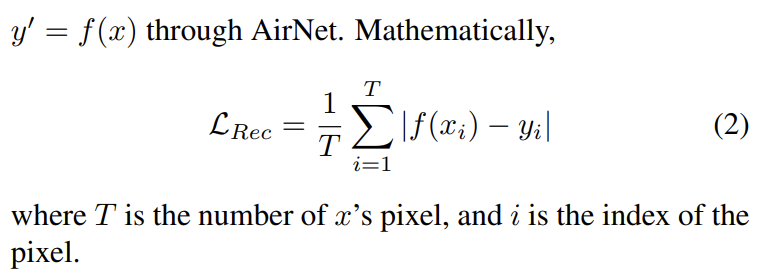
다음으로 contrastive based로 loss를 적용하는 방식이다. CBDE를 통해 얻은 z는 degradation에 대한 정보가 들어있는 representation이다. 따라서 같은 degradation에 대해서는 유사도가 높아야하고 (positive sample) 다른 degradation에 대해서는 유사도가 낮아야한다 (negative sample). 이를 loss function에 적용한다. 여기서 positive sample과 negative sample을 얻는 방법을 살펴보면, 이미지에서 랜덤하게 patch를 따오는건데 같은 이미지에서 patch를 따오면 같은 degradation이 있을 것이기 때문에 positive pair로 놓고 다른 이미지에서 patch를 따오면 다른 degradation이 있을 것이기 때문에 negative pair로 놓는다. 따라서 최종 Lcl 은 아래와 같은 식이 된다.
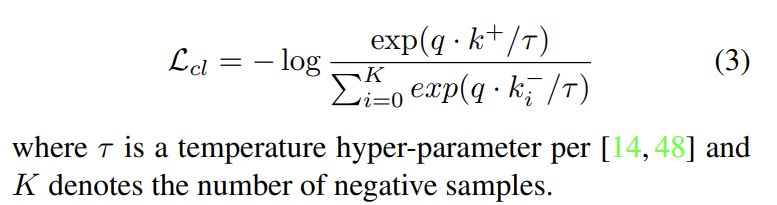
q가 기본 degradation이라고 하면 k+는 positive pair, k–는 negative pair가 되어 q와 k+의 내적값은 커지게, q와 k–의 내적값은 작아지게 만드는 loss function이 된다.
원래 노이즈 타입에 따라 수학적으로 접근해서 제거하곤 했는데 이렇게 학습하면 그럴 필요가 없어지고 다양한 degradation에 대한 representation을 학습할 수 있게 된다. 또한 위 Figure의 (b)를 보면 representation을 학습하기 위해 z를 얻어낸 후 convolution을 더 거쳐 representation을 얻고 z는 input과 output의 dimension과 같게 만들어서 z에서는 context를 최대한 유지하고 concat등에 사용하기 쉽게 만들었다고 한다. 이 z가 degradation에 대한 정보를 갖고 있다고 가정하기 때문에 뒤에서 많은 역할을 한다.
DGM (Degradation-Guided Module)
이렇게 얻어낸 z를 활용하는 방법은 2가지로 나뉘는데, z와 feature를 이용해 Deformable Convolution Netowrk(DCN)을 적용하는 과정, 그리고 z로 feature 자체의 distribution을 조정하는 Spatial Feature Transform(SFT) 파트가 있다. 밑의 그림이 이를 잘 나타낸다.

DCN이란 아래 그림처럼 convolution network에서 receptive field를 유연하게 조절할 수 있는 네트워크를 말한다.
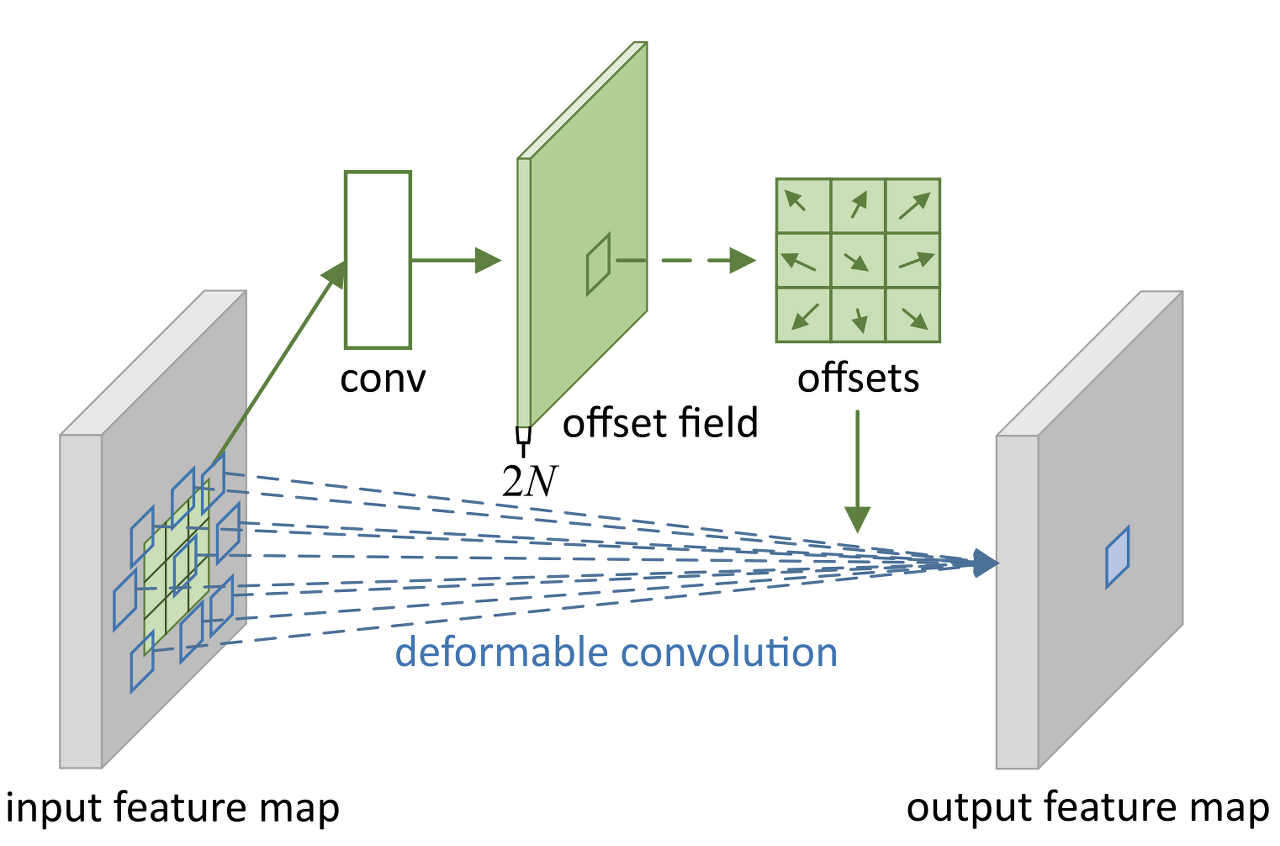
원래 convolution network를 쓸 때는 고정된 receptive field를 가질 수 밖에 없는데 이 receptive field를 정해주는 convolution을 중간에 넣어서 offset을 얻어내고 이렇게 얻어낸 offset으로 이동된 pixel들과 convolution을 적용해서 output을 얻어낼 수 있다. 식으로 표현하면 아래와 같다.
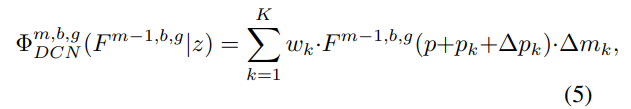
z에서 convolution을 통과시켜 \( \Delta \) pk와 \( \Delta \) mk를 얻어내서 offset을 유연하게 정할 수 있다. 이는 degradation의 종류에 따라 네트워크가 다른 receptive field를 가져야하기 때문에 위와 같은 방식을 적용했다고 할 수 있다. 그리고 feature 자체도 다른 degradation에 따라 다른 조정을 거쳐주게 하기 위해 z에서 convolution을 통해 \( \gamma \) 와 \( \beta \) 를 얻어내서 feature를 조절한다. 식으로 표현하면 아래와 같다.
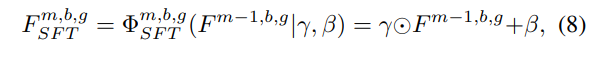
위의 과정이 하나의 모듈로써 작동하고 이 모듈들과 일반 convolution을 결합해 group으로 만들고 group을 여러개 쌓아 전체 DGRN (Degradation Guided Restoration Network) 이 된다.
Experiments
training dataset으로는 denoising – BSD 400, WED / deraining – Rain100L / dehazing – RESIDE를 사용했다고 한다. 밑의 table에서 one-by-one은 각각 denoising / deraining /dehazing을 따로따로 학습시킨 결과이고 all-in-one은 한번에 학습시킨 결과이다.
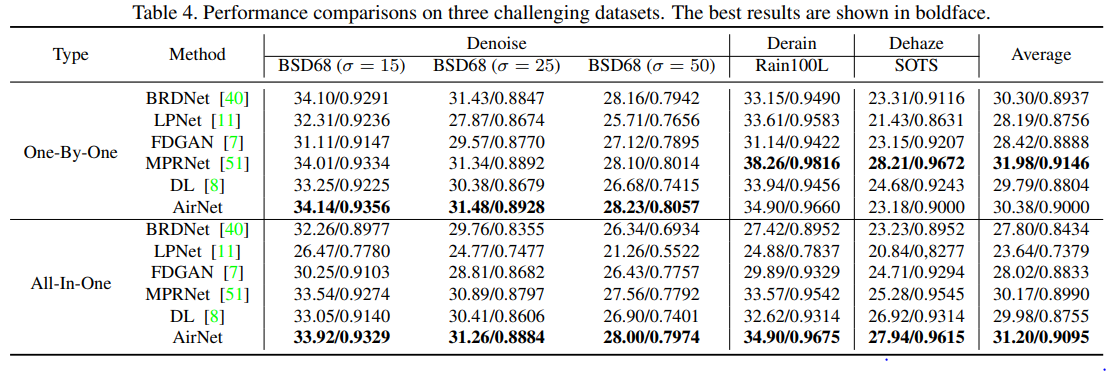
one-by-one에서는 MPRNet이 평균적으로 성능이 가장 좋긴 했지만 AirNet자체가 multi task를 위해 고안된 네트워크인 만큼 all-in-one에서 성능이 좋다. 다른 네트워크들은 all-in-one으로 했을 때 one-by-one보다 평균 성능이 거의 다 떨어지는데 AirNet에서는 오른다.
아래는 training할 때 denoising / deraining / dehazing 조합을 다르게 했을 때의 결과이다.
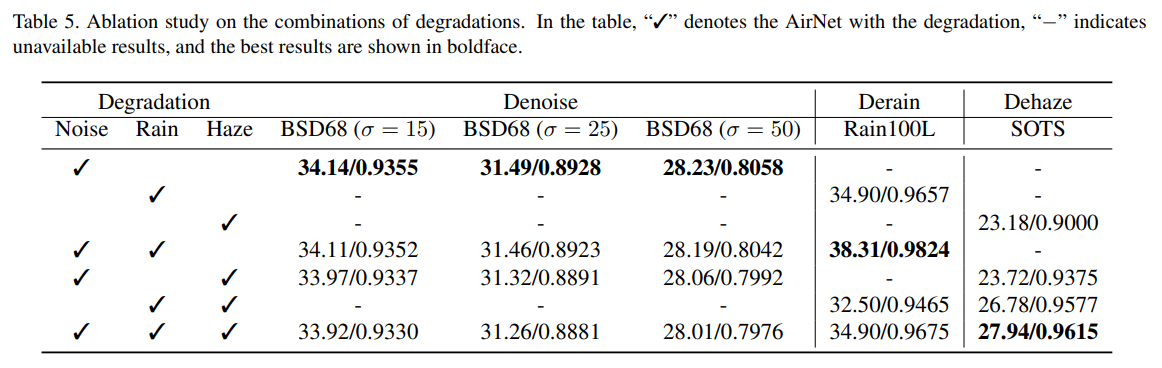
Conclusion
다양한 degradation에 대해 한번에 복원할 수 있는 네트워크. blur나 snow 등 다른 noise에 대해서도 잘 작동할지 확인해보면 좋을 것 같다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.