Introduction
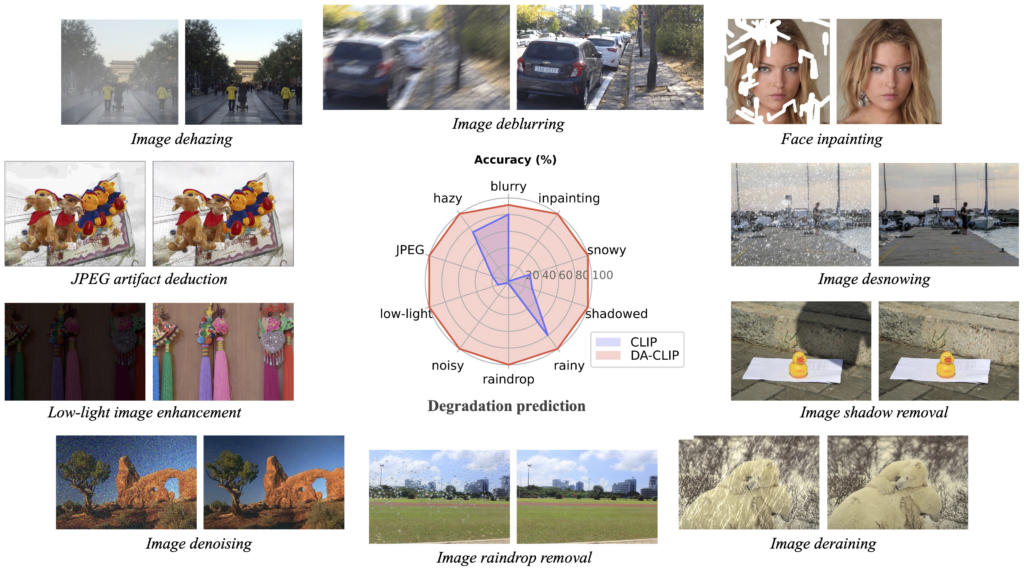
이전의 CVPR 2022 AirNet (All-in-one Image Restoration) 이후에 universal한 image restoration 네트워크를 만들고자 하는 노력이 이어지고 있다. 이번 논문은 CLIP을 이용하여 Clean 이미지, degradation type 등의 정보를 더 잘 추출할 수 있도록 학습시키는 방법을 제안한다. CLIP을 단순하게 그대로 사용하는 것이 아니라 Image Restoration에 맞게 약간 변형하여 사용하여 Degradation Aware CLIP (DA-CLIP) 이라고 부르고 아래와 같이 10개의 task를 한번에 다룰 수 있는 하나의 모델을 학습시켰으며 성능이 매우 좋다고 한다. (baseline은 IR-SDE paper를 이용하였고 diffusion을 사용하는 방식이다. 이전 포스팅에 설명이 되어있으니 필요하면 참고 https://doinghun.com/image-restoration-with-mean-reverting-stochastic-differential-equations-icml-2023/ )
Method
제안하는 방법의 overview는 아래와 같다. 먼저 (a)방법으로 기존 CLIP을 이용하여 Degradation-aware CLIP으로 만드는 학습과정이 있고 (a)에서 학습된 모델을 이용하여 (b)에서 이미지 복원이 이루어진다.
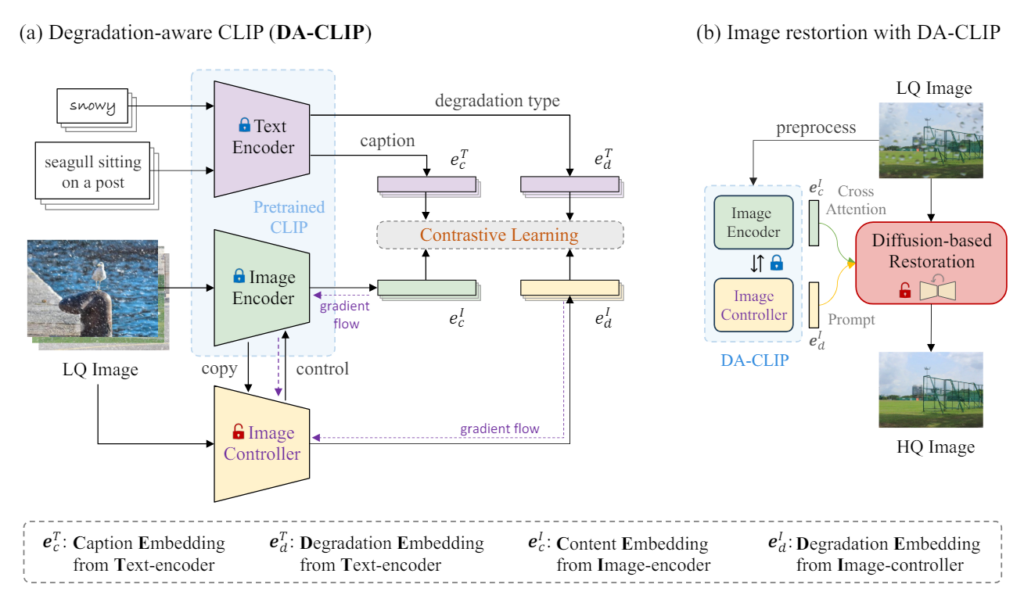
(a) Degradation-aware CLIP (DA-CLIP)
DA-CLIP은 크게 3개의 구성요소를 가진다. 1. Text Encoder, 2. Image Encoder, 3. Image Controller 이다. 여기서 1,2에 해당하는 Text Encoder와 Image Encoder는 Pre-trained CLIP을 그대로 이용하여 학습을 시키지는 않는다. 유일하게 학습시키는 네트워크는 3. Image Controller 이다. 그런데 Image Controller에서 Image Encoder로 connection을 연결하여 추가적인 정보가 Image Encoder로 들어가 결괏값에서 Image Controller의 영향을 받는다. 각각의 구성요소가 하는 일을 조금 자세히 봐보자.
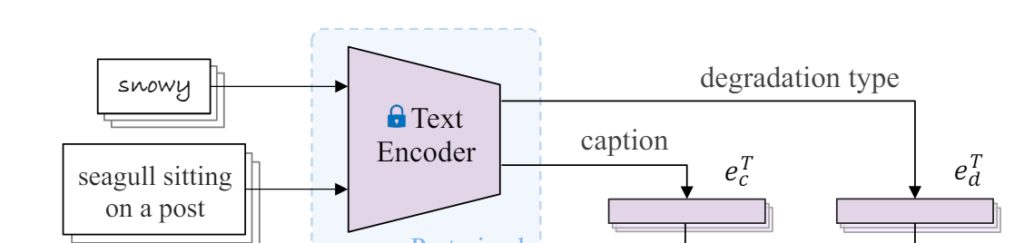
- Text Encoder : 1. 이미지를 설명하는 text와 2. 이미지에 들어있는 degradation type에 대한 text를 받아서 각각의 embedding (\(e^T_c\), \(e^T_d\))을 얻어준다. 여기서 1. 이미지를 설명하는 text에서 embedding을 얻을 때 사용하는 이미지는 clean한 이미지의 text를 사용하기 때문에 \(e^T_c\)는 clean한 이미지의 text에 대한 embedding을 얻게되고 2. \(e^T_d\) 는 degradation type에 대한 embedding을 얻게된다.
- Image Encoder : Image endcoder는 LQ(Low Quality) 이미지로부터 embedding을 얻는다. 이때 Image Controller와 connection으로 연결되어 있어서 Image Controller로 부터도 정보를 받아 embedding(\(e^I_c\))을 얻는다.
- Image Controller : 마찬가지로 LQ(Low Quality) 이미지로부터 embedding(\(e^I_d\))을 얻는다.
두 네트워크는 아래와 같은 형태로 연결되어 사용된다. 왼쪽이 Image encoder, 오른쪽이 Image controller 이다.
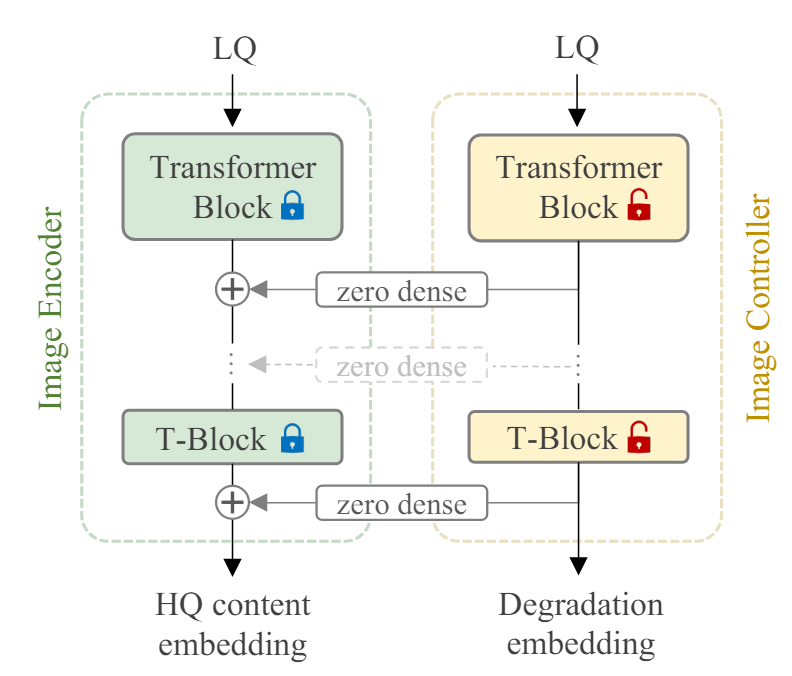
그림에 보면 Image Encoder는 HQ(High Quality) embedding, Image Controller는 Degradation embedding 을 output으로 내보낸다고 되어 있는데 이렇게 degradation type에 대한 정보, clean 이미지에 대한 정보를 잘 구분하여 추출하려는것이 이 DA-CLIP의 main 목적이다. 따라서 이를 위해 앞의 Text encoder로 부터 얻었던 embedding과 contrastive learning을 진행한다.
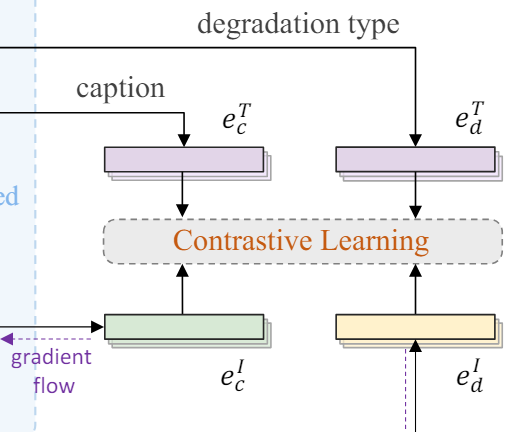
즉, clean한 text로부터 뽑아낸 embedding인 \(e^T_c\)는 clean한 정보를 가지고 있을 것이기 때문에 image encoder에서 얻은 embedding(\(e^I_c\))과 contrastive learning을 해줘서 유사하게 만들어주고
Degradation type에서 뽑아낸 embedding인 (\(e^I_d\))는 type에 대한 정보를 가지고 있을 것이기 때문에 image controller에서 얻은 embedding(\(e^I_d\))과 유사하게 만들어 준다.
이러면 각각 image encoder와 controller의 embedding을 하나는 clean한 정보, 하나는 degradation type에 대한 정보로 분리하여 뽑아낼 수 있고 이러한 정보가 여러 task를 하나의 모델로 다룰 수 있도록 도와준다.
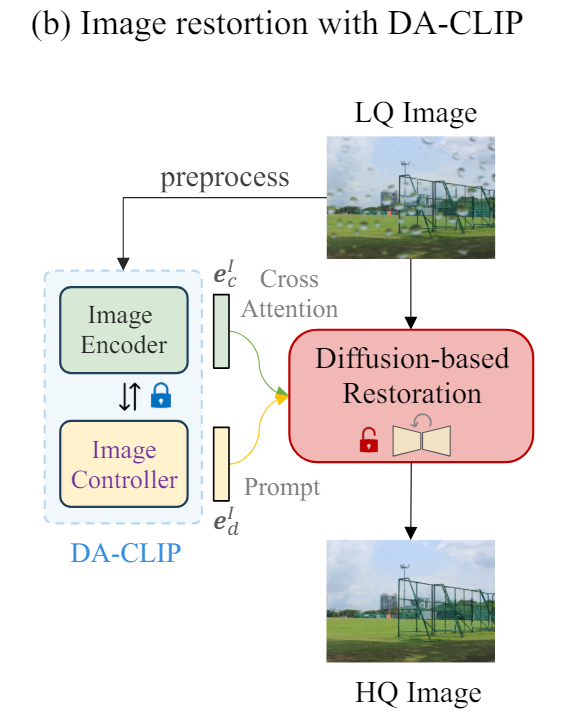
(b) Image Restoration with DA-CLIP
최종적으로 Image encoder에서 얻은 정보를 diffusion-based에서 cross attention으로 녹여서 사용해주고 Image controller에서 얻은 정보를 prompt로 추가하여 type에 대한 일종의 prompt로써 사용하게 된다.
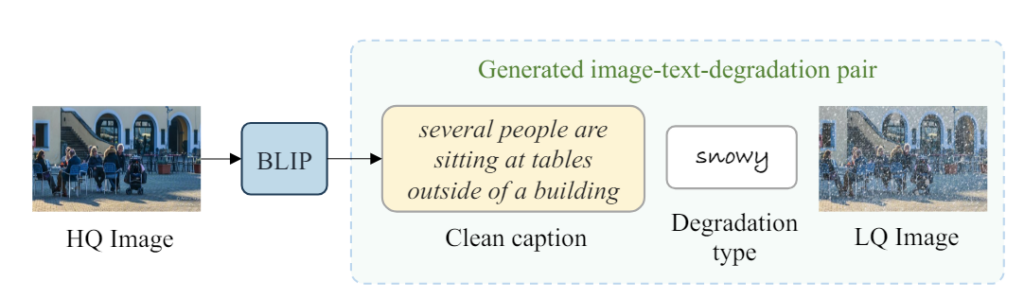
Dataset Construction
Image Restoration 분야에서 image-text가 pair로 존재하는 데이터셋이 없기 때문에 caption을 얻기 위해 BLIP을 사용하여 Clean 한 이미지로 부터 text를 생성하여 사용하였다고 한다. degradation type은 그냥 정해져있으니까 정해진 type대로 text를 만들어 사용하였다.
최종적으로는 아래와 같이 각 task의 dataset을 한번에 학습시키게 된다.

Experiments
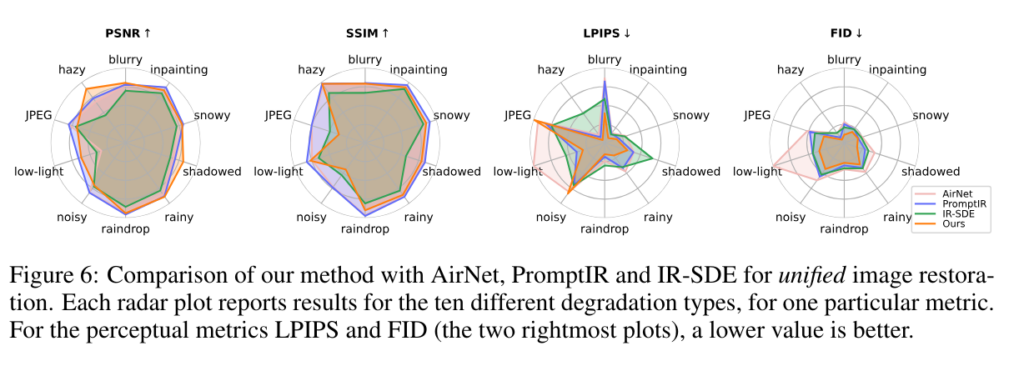
기본적으로 다른 all-in-one method들과 성능 비교를 해보면 꽤 좋다. 특히 LPIPS와 FID같은 perceptual 한 metric에서 더 좋은 느낌이다.

Conclusion
clean image embedding과 degradation type을 분리해서 얻어내는 것 자체가 universal network를 학습시키는데 도움이 된다는 말도 납득이 가고 이를 위해 CLIP을 매우 잘 활용한 예시인 것 같고 novelty도 좋은 논문 같다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.