Intro
이번에 소개할 논문은 DeblurGAN 이란 논문이다. 아래 그림이 Deblur가 뭔지, 어떤 도움을 주는지 잘 보여준다.

위의 사진이 blur가 있는 사진, 아래 사진이 clean한 사진이고 가운데 사진은 DeblurGAN을 통해 blur를 제거하여 만든 사진이다. 이를 이용해 object detection을 해보면 blur가 있는 사진에서는 bowl은 잡히지도 않고 사람도 못 잡는 경우가 있는데 DeblurGAN을 통해 blur를 제거하니 object detection이 상대적으로 다시 원할하게 되는 모습이다. Image Restoration 분야는 이런식으로 다른 classification이나 object detection등의 task들을 더 잘 할 수 있게 도와주는 역할로도 사용을 할 수 있고 이미지 품질 자체를 올려준다는 점에서 중요한 task중 하나이다.
Method
이제 이 논문에서 제시하는 Deblurring 방법을 살펴보자.
사실 굉장히 간단한 GAN을 사용하는 방식이다. GAN(Generative Adversarial Network) 이란 Generator와 Discriminator를 만들고 Generator는 최대한 real한 이미지를 만들도록 학습되고 Discriminator는 real이미지인지 Generator로부터 생성된 이미지인지를 구별하도록 학습되는 형태의 이미지 생성 모델인데 이 구조를 Deblurring에 가져와서 Geneartor가 blur이미지를 받아 clean 이미지를 생성하도록 학습하는 식이다. 정확히는 WGAN 구조를 사용하는데 GAN구조에서 loss function만 살짝 바뀐 형태이다.
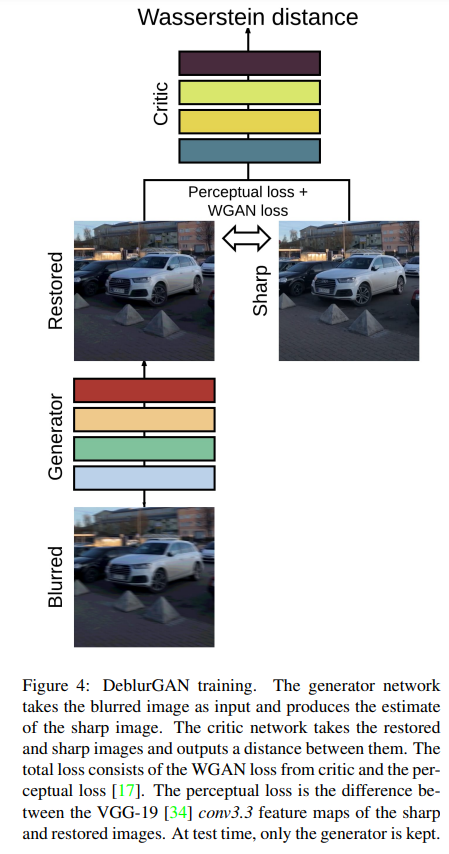
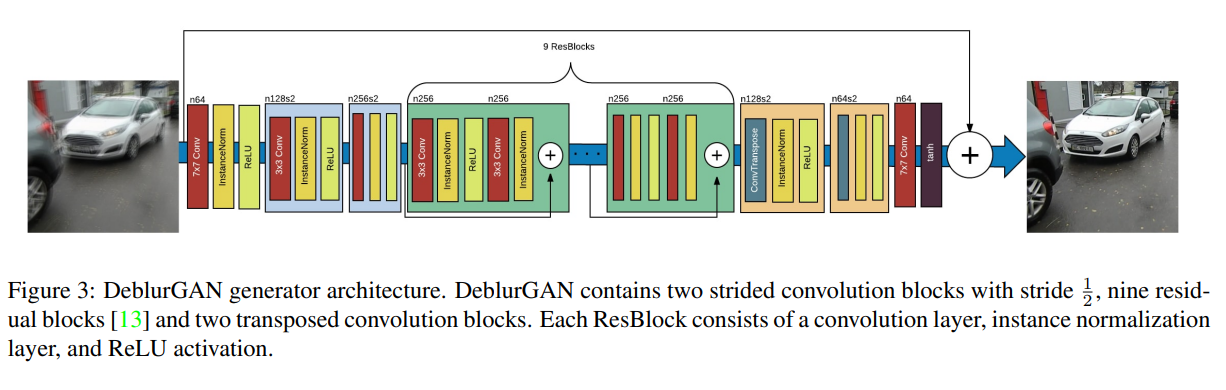
Generator의 구조는 크게 특별한 것은 없이 residual connection과 CNN들을 결합한 형태이고 denoising 모델인 DnCNN 구조와도 비슷하다.
이제 사용한 Loss function을 살펴보자.
먼저 adversarial loss이다. WGAN-GP 방식을 사용하고 이 방식이 generator의 architecture 선택을 더 robust하게 해준다고 한다. 식은 아래와 같다.
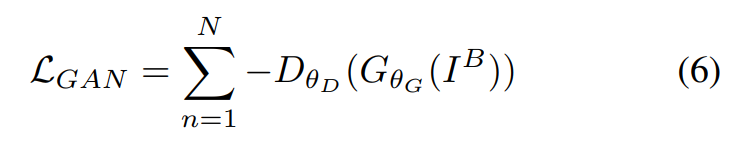
IB는 blur 이미지이고 G는 Generator, D는 Discriminator이다. Discriminator는 real clean 이미지로 판단하면 큰 값, 아니면 작은 값으로 output을 내놓기 때문에 위 식은 즉, Generator로 통해 나온 이미지를 Discriminator가 real로 판단할수 있도록 Generator를 훈련시키는 loss function이 된다.
다음은 content loss function이다. perceuptual loss를 사용하는데, VGG 네트워크에 clean 이미지와 generator에서 생성된 이미지를 넣어서 feature map끼리 L2-loss를 걸어서 같아지도록 만든다. 식은 아래와 같다.

\( \phi \)는 VGG에서 conv3.3을 통과한 feature map을 얻어내는 함수라고 생각하면 된다. W와 H는 feature map의 Width와 Height이고 IS는 clean 이미지 IB는 blur이미지 G는 generator가 된다. 즉, Generator에서 생성된 이미지와 clean 이미지가 VGG 네트워크를 통과하고 conv3.3 을 통과했을 때의 각 feature map의 L2-loss를 줄이는 함수가 된다.
이 두 loss function을 합쳐 최종 loss function을 얻는다.
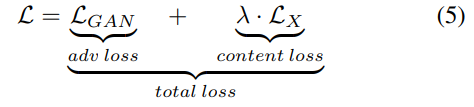
사실 LGAN을 쓰지 않아도 네트워크가 수렴한다고 한다. 그래도 쓰는게 더 좋은 결과가 나온다고 한다.
여기에 추가적으로 motion blur generation에 대한 이야기도 있는데 요약하면 synthetic하게 blur를 만들어내어 학습에 추가적으로 사용했다는 이야기이다. 아래 사진을 보면 흔들린 이미지와 원래 이미지가 있으면 어떻게 사진이 흔들렸는지 motion trajectory를 얻을 수 있고 이게 blur kernel이 된다.
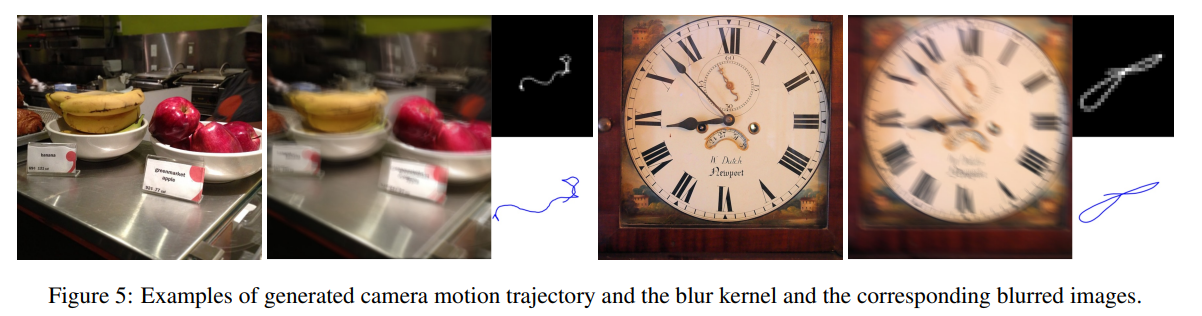
이 blur kernel을 synthetic하게 만드는데 요약하면 특정포인트에서 다음포인트를 만들 때, 이전 포인트들의 위치, 속도, perturbation 등을 고려해서 다음 포인트를 그려나가며 random하면서도 리얼하게 만들었다고 한다. 이 blur kernel을 이용해 흔들린 이미지를 dataset에서 추가로 만들어 학습에 활용해 real blur dataset에서 조금 더 성능을 올렸다.
성능요약
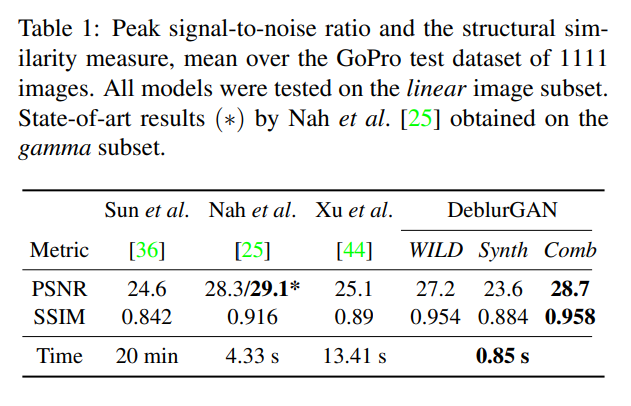
: GoPro 데이터셋 (1111장의 test dataset) 에서 synthetic한 blur kernel까지 학습에 활용하면 psnr이 28.7 db. synthetic한 blur kernel 없이 DeblurGAN만 적용하면 27.2 db 정도 나온다.
Conclusion
GAN 방식을 이용한 Deblurring 네트워크이다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.