흔히 Denoising/Deblurring 같은 이미지 복원 task를 위해서 딥러닝 모델을 학습시킨다고 했을 때 사용하는 방법은 Noise/Clean 데이터 쌍을 모아서 네트워크에 보여주면서 네트워크가 noisy image와 clean image의 차이를 학습하고 noisy 이미지에서 noise만 제거해 clean한 이미지를 만들도록 하는 것이다.
그런데 이 Deep Image Prior 논문은 clean image가 아예 없어도 네트워크는 자연스러운 이미지에 대한 prior(사전 지식)을 가지고 있기 때문에 그냥 noise 이미지 하나만 있어도 clean 이미지를 만들어 낼 수 있다고 얘기한다. 이 논문에서 제시하는 방식은 아래와 같다.
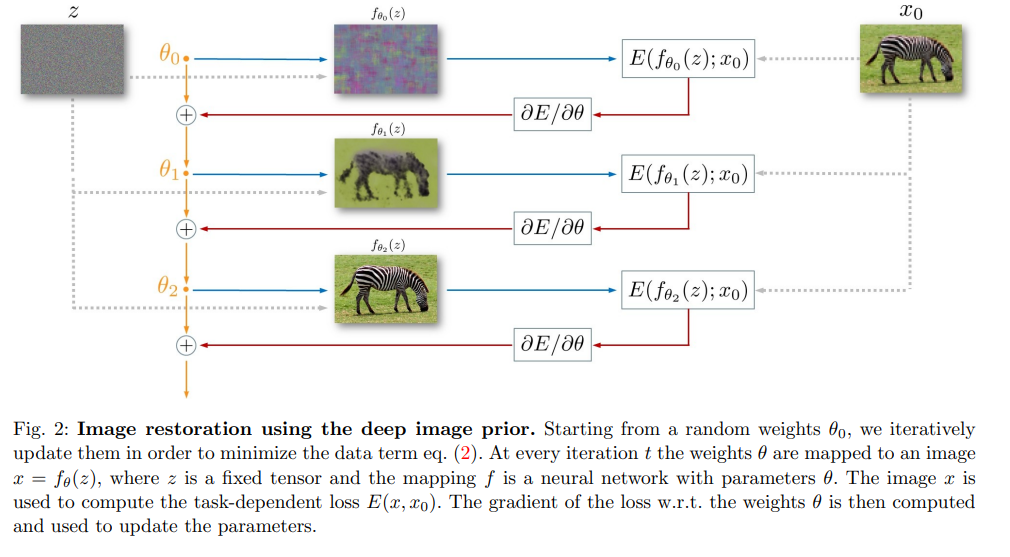
먼저 네트워크에 random한 input (z)를 넣는다. 이 z는 그냥 랜덤하게 얻어낸 input이고 고정시켜 사용한다. 네트워크는 이 고정된 input을 계속 받으면서 목표 이미지 x0를 생성하도록 파라미터가 업데이트 된다. 이때 목표 이미지는 그냥 noisy image가 사용된다. 따라서 이 과정에서 clean 이미지는 전혀 사용되지 않는다. 그럼에도 불구하고 위의 과정대로 네트워크를 학습시키다 보면 중간 과정에서 clean한 이미지가 생성된다. 너무 많이 파라미터를 업데이트하면 목표 이미지 x0를 그대로 생성해버리게 되고 중간에 적당히 멈추면 목표 이미지보다 더 좋은 품질의 이미지를 얻을 수 있다.
어떻게 이런 일이 가능한 지에 대해서 이 논문에서는 네트워크가 자체적으로 이미지에 대한 prior(사전지식)을 갖고 있다고 주장하며 아래와 같은 그래프로 그에 대한 근거를 제시한다.
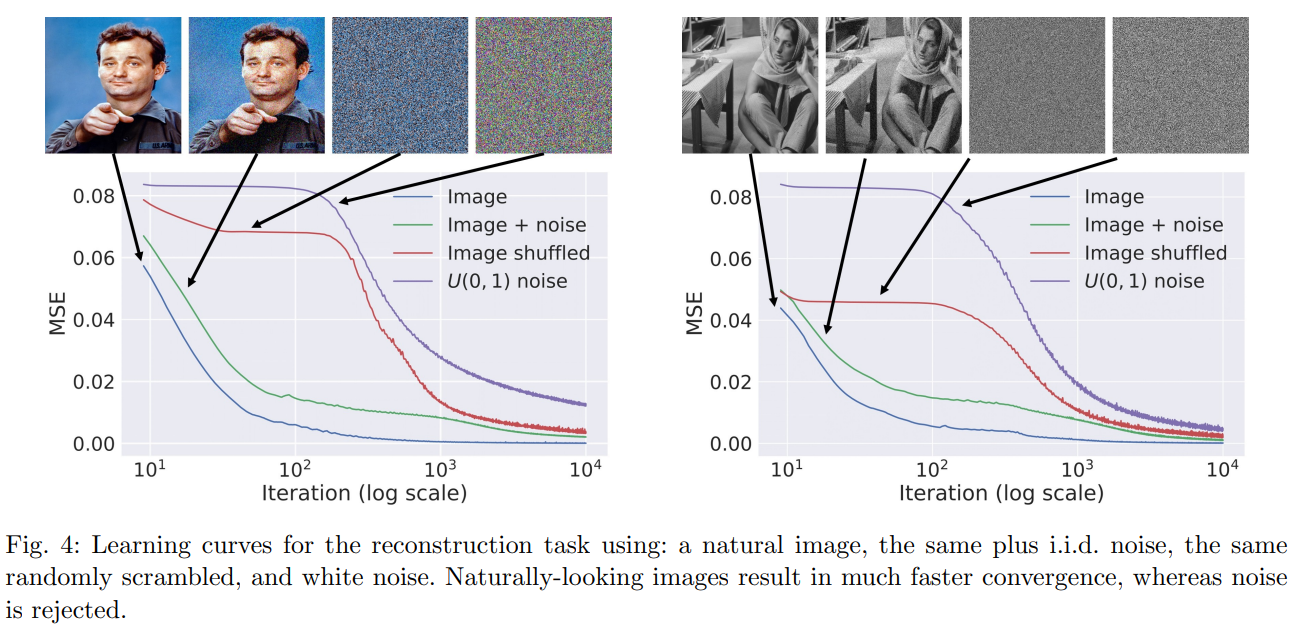
이 그래프들은 이 논문에서 제시한 방법대로 네트워크가 목표 이미지를 생성하도록 했을 때의 Loss의 변화 추세를 나타낸것이다. clean 이미지, noisy 이미지, clean 이미지에서 pixel을 랜덤하게 섞어버린 이미지, 그냥 random gaussian noise, 이 4가지 이미지를 이용해서 loss 변화 추세를 보여주는데 자연스러운 이미지인 clean 이미지는 네트워크가 쉽게 생성을 해내는데 noise가 섞이고 부자연스러운 이미지를 생성하려고 하면 네트워크가 조금 어려워 한다. 물론 iteration을 많이 돌리면 결국에 그냥 noise도 똑같이 생성을 하긴 하지만 clean하고 자연스러운 이미지보다 오래걸리고 어려워한다는 것을 알 수 있다. 이 것이 네트워크가 자연스러운 이미지에 대한 prior를 가지고 있다고 주장하는 근거이다.
밑의 figure가 이 예시를 잘 보여준다.

JPEG로 손상된 이미지를 이 논문에서 제안한 방식으로 복원하는건데 50K iteartion을 해버리면 손상된 이미지와 거의 완전히 동일한 이미지를 생성하게 되지만 2400 iteration에서 끊으면 원래보다 더 좋은 품질의 이미지를 얻을 수 있다.
전체적으로 정리해보자면,
- Clean image가 전혀 없어도 이미지 자체의 prior를 네트워크가 가지고 있어서 noise나 low resolution의 이미지를 더 좋은 품질로 생성하는 것이 가능
- 하지만 이렇게 학습시켜서 얻어낸 네트워크는 그 이미지 하나만 생성할 수 있는 네트워크고 다른 이미지는 또 같은 방법으로 새로 학습시켜야 되기 때문에 비효율적일 수 있음. 즉 clean 이미지 한 장을 얻기 위해 네트워크 하나를 학습시켜야 되기 때문에 비효율적임. 실제로 이미지 한장당 약 30분 정도가 소요된다고 함.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.