Abstract
일반적으로 고정된 크기의 convolution filter를 사용하는 방법은 한번에 이미지의 global한 정보를 다루기 어렵다. global한 정보를 얻기 위해 더 큰 recpetive field를 만들기 위해서는 kernel size를 늘리거나 convolution filter를 여러개 쌓는 등의 방법을 적용해야하는데 이는 연산량을 늘리고 네트워크를 무겁게 만든다. 이 논문에서는 이를 Fourier tranformation을 통해 해결한다. Fourier domian에서는 point하나 하나가 이미지의 global한 정보를 담고 있기 때문에 1×1 kernel만으로도 global한 정보를 이용해 학습을 할 수 있다는 것이다. 이를 이용해 기존 네트워크를 그대로 이용하면서 Fast Fourier Convolution (FFC) 방법을 적용해 성능을 올리는 방법 및 실험 결과들을 보여준다.
Introduction
FFC를 고안하게 된 2가지 주요 포인트들에 대해 설명한다.
1. 큰 receptive field의 필요성 – 일반적인 neural network에서는 작은 사이즈의 filter를 주로 사용한다. (e.g. 3×3 filter). 이런 필터들로는 한번에 이미지의 global한 정보를 얻기 어렵고 따라서 네트워크를 deep 하게 만들고 여러 convolution layer를 쌓아서 high level의 layer에서는 global한 정보가 다뤄지게끔 만드는게 일반적이다. 또한 human pose estimation 같은 context-sensitive task 에서는 큰 receptive filed가 더욱 필요하다고 한다. 이를 위해 최근에 deformable convolution이나 non-local neural network 등의 방법을 통해 recpetive field를 키운다고 한다.
2. fusing multi-scale information – low level layer의 정보부터 high level layer의 정보를 모두 이용하는 방식은 네트워크 성능향상에 많은 영향을 끼쳤다. HRNet, Auto-DeepLab 등등 이를 이용해 성공적인 결과를 얻은 네트워크들도 많고 이 논문에서도 multi-scale information을 활용하기 위한 방법을 고려해 FFC 방법을 설계했다고 한다.
이 두가지 점을 고려하여 FFC 방법을 설계하였고 local한 receptive field와 non-local한 receptive field의 정보를 같이 이용하도록 하였다. 또한 기존의 vanilla convolution에 FFC 방법을 적용하도록 바꾸는 것이 쉬워서 활용가능성이 높다고 한다.
Related Work
Non-local neural network
최근 연구들에서 한 layer안에 있는 distant neurons를 연결해 활용하는 것이 점점 중요해지고 있다고 한다. 이처럼 한 layer안의 다른 neuron 정보를 활용하는 것을 non-local network라고 하고. 기존의 연구들에서는 이를 위해 다양한 방법을 이용한다(e.g., 그림1). 위에서 얘기했듯 이는 연산량을 증가시키고 실제로 잘 활용하기 위해서 acceleration같은 추가적인 연구가 더 필요하다고 말한다.
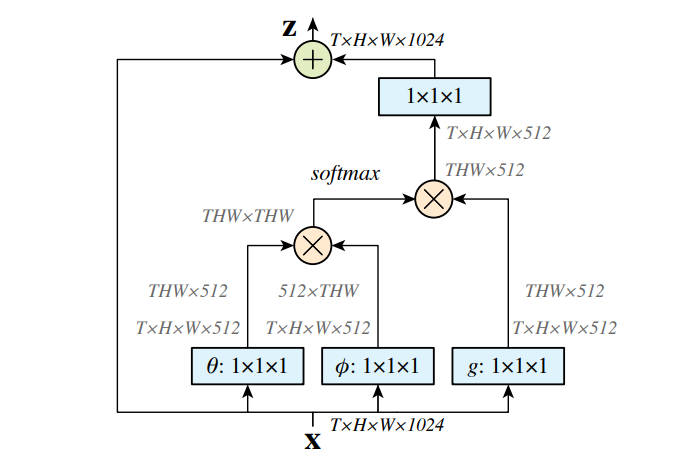
Cross-scale fusion
그림2에서 볼 수 있듯이 neural network에서 각각의 layer 정보들은 다른 의미를 가지며 이를 잘 섞어 활용하는 것이 중요하다. FCN에서는 different scale의 feature map을 concate해서 활용하고, HRNet은 multiple branch를 만들어 cross-scale fusion에 활용하는 등 다양한 방법들이 있다.
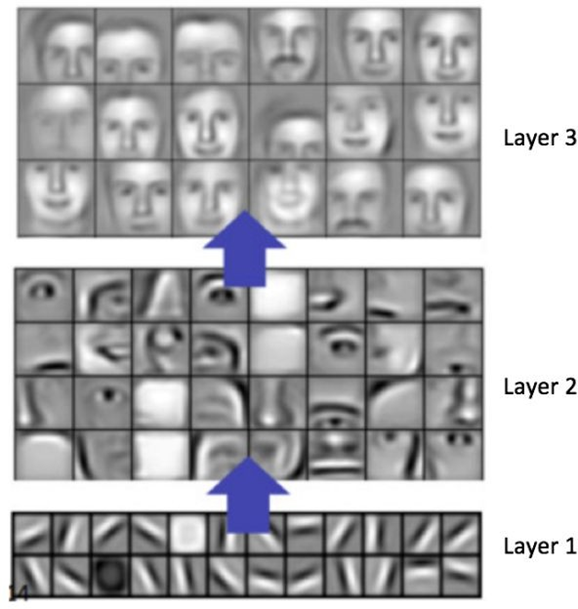
Spectral neural networks
최근 spectral neural network에 대한 연구가 점점 늘어나고 있다고 한다. 보통 convolution 연산을 가속하거나 deep network를 구성하는 block으로 쓰이는 등 다양하게 적용되고 있는데 이 연구에서는 기존 방법들과 다르게 Fourier transform을 이용해 새로운 operation unit을 만들고 spatial 정보와 spectral 정보를 같이 이용하는 방법을 제시한다.
Fast Fourier Convolution (FFC)
Architecture design
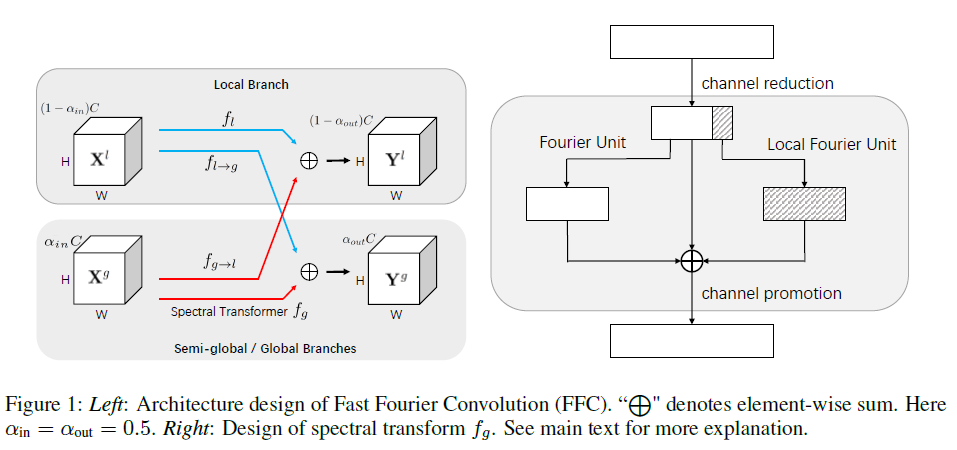
기본적인 architecture 구조는 위의 그림과 같다.
X라는 input feature map이 있다고 하면 이를 채널기준으로 둘로 나눠 Xl과 Xg으로 나눈다. 이 둘을 이용해 아래의 식으로 output Yl과 Yg 을 만든다.
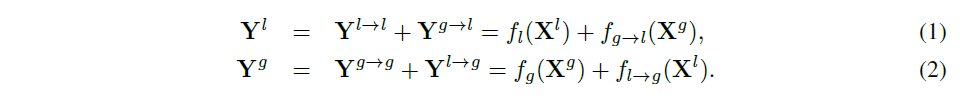
위의 (1),(2) 식에서 쓰인 fg를 제외하면 모두 일반적인 convolution을 이용한다. 이 논문에서는 이 fg를 spectral transformer라고 부른다.
Spectral transformer
그림 3의 오른쪽이 Spectral tranformer의 자세한 묘사이다. 먼저 input을 1×1 convolution을 이용해 채널을 반으로 줄인다. 줄어든 input은 Fourier Unit을 통해 한번 연산이 되고 줄어든 input의 1/4은 Local Fourier Unit의 연산에 이용된다. 이후 둘과 줄어든 input을 합하고 다시 1×1 convolution을 통해 원래 채널 사이즈로 키워준다. 이러한 연산의 의도는 FU를 통해 global receptive field를 얻고 LFU를 통해 semi global receptive field를 얻어 같이 이용하는 것이다.
Fourier Unit
자세한 FU 알고리즘은 아래와 같다. 실수와 허수부를 각각 분리하고 허수부를 실수처럼 취급해 채널기준으로 concate하여 활용한다. 중간에 W가 절반이 된 이유는 Fourier transformation이 symmetric한 성질을 가지고 있기 때문에 변환된 이미지의 절반만 활용해도 상관없기 때문이다. 이후 1×1 convolution, batch normalization, relu연산을 적용하고 다시 원래대로 inverse fft를 적용해 내보낸다.

Local Fourier Unit
LFU의 방법은 아래와 같다. 1/4의 input feature를 H,W기준으로 4등분해서 채널기준으로 concat하고 FU를 적용한뒤 spatial shift를 이용해 replicate해서 다시 원래 H,W로 만들어준다. spatial shift는 ‘TSM: Temporal shift module for efficient video understanding’ In ICCV, 2019. 논문의 방식을 참고해 사용했다고 한다.

LFU는 FU에 비해 channel size가 증가해 연산량이 많다고 한다. 근데 FU보다 채널이 1/4배 작은 input을 쓰니까 같은거 아닌가..? 이 부분은 잘 이해가 가지 않는다.
Compatibility with vanilla convolutions.
위에서 언급했듯이 이 architecture에서 fg를 제외하면 모두 일반적인 convolution을 이용하고 fg에서도 fourier domain의 값들을 모두 real로 취급하고 1×1 convolution에 적용하기 때문에 fully differentiable해서 일반적인 다른 네트워크들에도 적용가능하다고 한다.
Extension to spatio-temporal video data
FFC에서 커널에 time축을 추가해 그대로 video에도 적용할 수 있다고 한다.
Complexity analysis

vanilla convolution과 parameter와 FLOPs를 비교했을 때 큰 차이가 나지 않는다고 한다. 또한 큰 kernel size를 요구하면 오히려 FFC 연산이 더 효율적으로 될 수 있다고 한다.
Experiments
실험은
ImageNet dataset에 대해 image classification,
Kinetics-400 dataset에 대해 video action classification,
Microsoft COCO keypoint benchmark 에서 Human keypoint detection에 적용해 결과를 보여주었다.
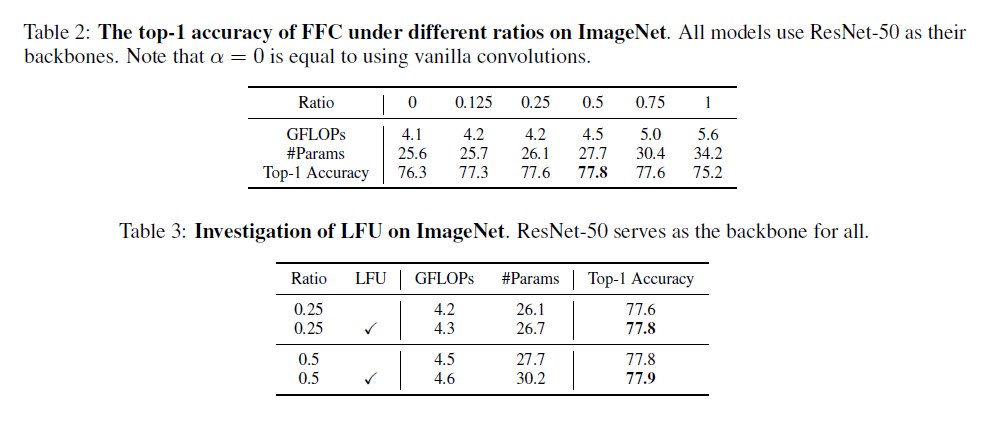
Table 2에서 \( \alpha \) 값은 Figure 1의 왼쪽 그림에서의 \( \alpha \) 값이고 0이면 FU 연산이 들어가지 않은 원래 모델 그대로가 된다. Table 2에서 보이다 시피 \( \alpha \) 값이 0.5일 때 가장 accuracy가 높게 나온 것을 볼 수 있다. 또한 Table3에서는 LFU를 추가하면 accuracy가 향상되는 것도 관찰할 수 있다.

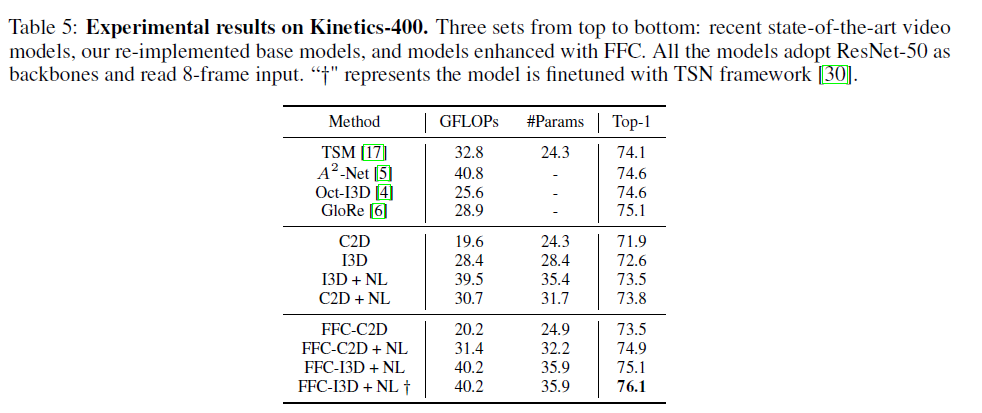
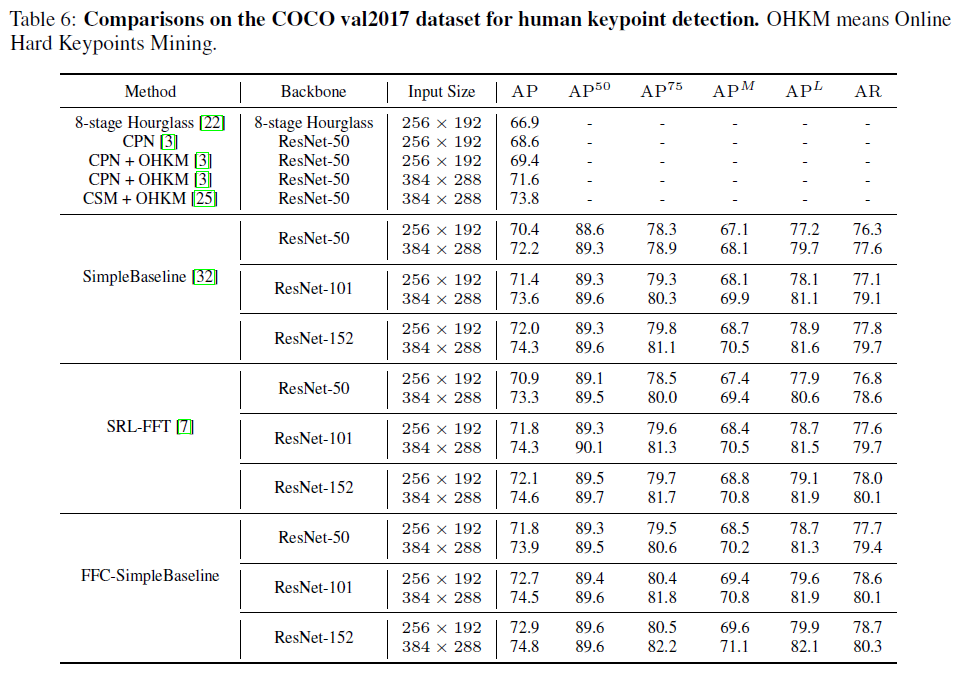
Table 4에서는 다른 state-of-art 방법들과 비교하고 있는데 FFC 방법이 연산량 및 정확도에서 굉장히 좋은 결과를 보여줌을 알 수 있다. 또한 밑의 Table 5, 6에서도 각각 FFC 방법이 기존 baseline 성능을 향상시키고 state-of-art 결과를 내는 것을 보여준다.
Conclusion
FFC 방법을 이용하여 non-local, scale-fused 네트워크를 만들 수 있었고 성능이 좋았다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.