2023년 CVPR에서 소개된 image editing 관련 논문이다. 전체적인 flow는 아래 그림과 같다. 먼저 GPT3, Stable Diffusion, Prompt2Prompt 등을 이용해 instruction과 image pair를 생성하여 학습용 데이터셋을 생성한다. 이후 Stable Diffusion 모델을 fine-tuning 하여 inference에서는 image와 instruction을 주면 그에 맞게 이미지가 바뀌는 식이다.

1. Introduction
기본적으로 human-written instruction 과 그에 해당하는 image pair 데이터는 구하기 쉽지가 않다. 따라서 이러한 데이터셋을 생성하여 학습에 사용하겠다는 것이 포인트이고 이렇게 생성한 synthetic 데이터셋으로만 학습시켰는데 real image들에서 instruction에 의한 editing이 굉장히 잘 되었다고 한다.
2. Prior work
GPT, Diffusion 모델에 대한 설명은 생략한다.
Generative models for image editing: 기본적으로 Diffusion 모델을 이용하여 image editing을 하려는 시도는 계속 있어왔다. 하지만 이때 가장 큰 문제가 Diffusion 모델은 similar text prompt를 사용한다고 similar image를 생성한다는 보장이 없다는 것이다. Cat을 생성하라고 한다고 완전히 똑같은 cat 이미지를 생성하지 않고 다양한 background, shape, location을 가진 이미지를 생성한다는 이야기이다. 이러한 문제를 해결하기 위해 Prompt-to-Prompt 방식이 제안되었는데 비슷한 text prompt에 대해서는 비슷한 이미지를 생성할 수 있도록 하는 방법이다. 이 방법을 이용해 학습용 데이터 생성에 이용한다.
Learning to follow instructions: 이 논문에서 제시하는 방법은 기존의 text-based image editing 방법과는 약간의 차이가 있다. 기존 방법들은 주로 이미지를 어떻게 변형시킬지instruction을 주는 것이 아니라 주로 원하는 결과 이미지의 description 혹은 caption을 주고 output 이미지를 얻는다. 이 두 방법은 비슷해 보이지만 output의 전체 description을 주려면 추가 설명들(ex. Background, object location, color)을 매번 주어야 하지만 instruction은 바꾸고자 하는 부분만 명시하면 돼서 더욱 효율적으로 image editing을 할 수 있다.
3. Method
전체적인 method는 위에서 설명했듯이 1. GPT와 Stable Diffusion을 이용한 학습데이터 생성 2. Image editing diffusion 모델의 training 단계로 나뉜다.
3.1 Generation Instructions and Paired Captions
먼저 instruction과 그에 해당하는 paired caption을 생성한다. 이를 위해 GPT를 사용해서 아래와 같이 input caption을 넣어줬을 때 instruction과 edited caption을 output으로 내보내도록 fine-tuning 시킨다. 학습 데이터는 LAION-Aesthetics V2 6.5+ 데이터셋에서 700개의 input caption을 sample로 가져오고 직접 manual하게 instruction과 output caption을 작성했다고 한다.

이렇게 학습시키면 아래 표와 같이 GPT가 새로운 instruction과 edited caption을 생성할 수 있게 되어 large size의 instruction과 paired caption을 가질 수 있게 된다. 생성에 사용한 input caption도 모두 LAION 데이터셋에서 가져온 caption이다.

이제 이러한 input caption과 edited caption을 가지고 paired image를 만들어야 하는데 위에서 언급했듯 일반적인 StableDiffusion으로 생성하면 아래 그림의 왼쪽과 같이 두 image가 사뭇 다른 형태로 출력될 가능성이 있다. 이를 위해 prompt-to-prompt 방법을 적용하면 아래 그림의 오른쪽처럼 원하는 부분만 바뀌고 서로 유사한 이미지로 생성되게 할 수 있다고 한다. Prompt-to-prompt의 작동 원리 설명은 생략하겠다.

이처럼 image editing을 위한 pair를 만드는데 또 중요한 것 중에 하나가 image에서 변화되는 양이다. 어떤 editing은 작은 물건 하나만 바꾸면 되지만 어떤 editing은 background 전체를 바꾸거나 물건의 위치를 바꾸는 등 변형이 많이 되어야 하기 때문이다. Prompt-to-prompt 에서는 p라는 변수로 이를 조절하는데 적절한 pair 이미지를 얻기 위해 p를 optimal로 얻는 것이 쉽지 않다고 한다. 이를 위해 각 caption pair마다 100개의 sample image pair를 p를 0.1~0.9로 랜덤으로 주어 생성한 다음 filtering 하여 사용하였다고 한다. filtering에는 CLIP-based metric을 사용했는데 input caption과 output caption의 거리 차이와 두 이미지 간의 거리차이의 consistency를 측정하여 filtering하였다고 한다. 이러한 방법이 image pair 생성의 quality를 굉장히 높여주고 robust하게 만들어주었다고 한다.
3.2 InstructPix2Pix
특별한 내용은 없는데 Stable Diffusion 모델을 fine-tuning 했다는 이야기이다.
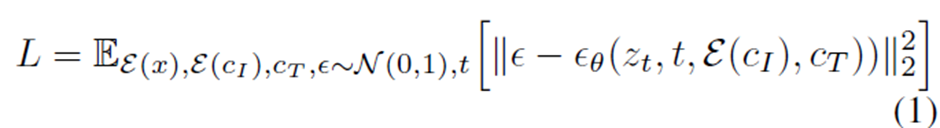
여기서 \(z_t\)는 noisy latent, \(t\)는 time step, \(\mathcal{E}\)는 Latent diffusion에 사용되는 encoder, \(c_I\)와 \(c_T\)는 각각 image condition과 text instruction conditioning 에 해당한다. 일반적인 stable diffusion을 학습시키는데 사용되는 loss 식이다.
3.2.1 Classifier-free Guidance for Two Conditionings
Classifier-free guidance란 diffusion model로 이미지를 생성할 때 이미지의 probability를 특정 class에 맞게 shift하는 방법이다. 일반적으로 diffusion model에서 unconditional과 conditional 세팅을 같이 학습을 같이 시키고 inference에서 아래와 같은 식으로 조절하는 방법이다.
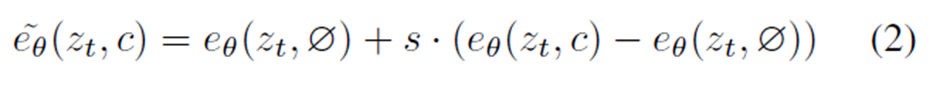
condition인 c 대신에 null(\(\emptyset\))값이 들어간 부분이 unconditional하게 estimate하는 부분이고 c가 들어가면 특정 class에 conditional하게 estimate 하게 된다. 즉 위 식에서 s값이 커지면 특정 class에 더욱 강하게 condition이 적용되는 것이다. s값을 1보다 키우면 일반적으로 class condition으로 생성하는 것 보다 더욱 강하게 특정 class에 condition을 주어 생성할 수가 있게 된다.
이 방법을 적용하여 이 모델에서도 학습할 때 데이터중 5%는 \(c_I\)를 null로, 5%는 \(c_T\)를 null로 또 5%는 \(c_I\)와 \(c_T\)를 둘다 null로 주어서 학습을 시키면서 inference에서는 아래와 같이 최종 estimate score를 얻는다.
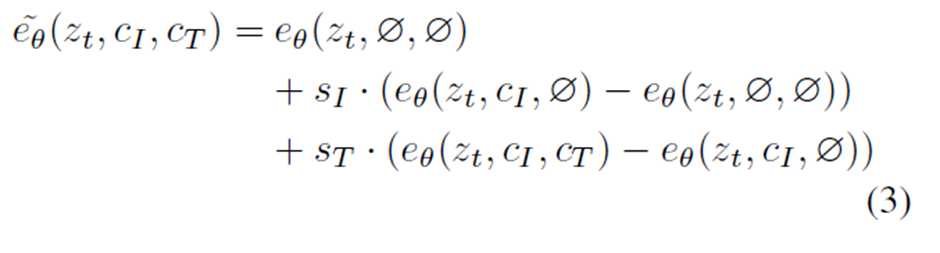
위 식을 보면 \(s_I\) 값을 키우면 Image condition에 더욱 강하게 condition이 걸리고 \(s_T\)값을 키우면 text instruction에 더욱 강하게 condition이 걸린다. 아래 그림을 보면 위의 결과를 잘 나타내준다.

다비드 석상을 사이보그로 만드는데 \(s_I\)값이 클수록 더욱 원래의 다비드 석상의 이미지를 많이 가지고 있고 \(s_I\)값을 줄이고 \(s_T\)값이 늘어날수록 원래의 image보다 사이보그 형태가 강하게 나타난다.
4. Results
qualitative 결과를 보면 아래와 같이 굉장히 성공적으로 작동하는 것을 볼 수 있다.

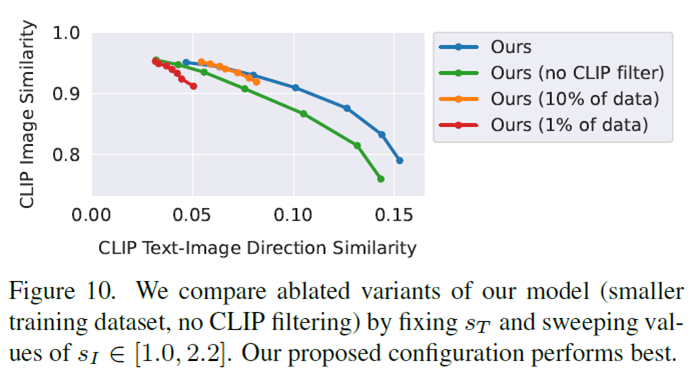
Ablation 으로는 CLIP filter를 적용했을 때, dataset 사이즈를 줄였을 때 등이 있는데 CLIP filter를 제거하면 전체적으로 성능이 떨어지고 dataset 사이즈를 줄이면 editing이 약간만 바뀌는것만 적용되고 large size의 editing은 작동을 잘 안 한다고 한다. 아래 그래프를 보면 나와있다.
5. Conclusion
이 방법은 기존의 diffusion모델과 GPT를 사용했기 때문에 이 두 모델의 성능에 의해 영영향 받는다. 또한 모델이나 data의 biases 에도 여전히 같은 영향을 받는다는 limitation이 있다. 몇까지 failure case또한 보여주는데 아래 그림처럼 viewpoint를 바꾸거나 특정 object를 isolate하게 바꾸거나 위치를 바꾸는 데에는 약한 모습을 보인다고 한다.

마지막 open question으로는 이러한 spatial reasoning을 어떻게 더 잘하게 할 건지, image editing에 대한 성능 평가를 어떻게 할 건지, human feedback을 적용하여 발전시키는 것 등이 있다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.