Abstract
많은 CNN 네트워크는 고정된 size의 이미지를 input으로 받는다. 이 과정에서 이미지를 원하는 size로 조정하기 위해 downsample 등을 하게 되는데 이 과정에서 정보를 손실하고 정확도가 떨어진다고 한다. 따라서 이 논문에서는 이러한 downsample을 frequency domain의 정보를 이용하여 tirvial frequency component를 줄이는 방식으로 진행하여 정확도 손실을 최소화 할 수 있었다고 한다.
Introduction
대부분의 CNN model들이 고정된 size의 input을 받는다 (eg. 224 x 224). 하지만 현대의 카메라부터 얻는 이미지나 high definition(HD) resolution의 이미지 같은 경우에는 1920 x 1080 의 size를 가지는 등 정해진 input size보다 큰 경우가 대부분이다. ImageNet dataset의 경우에도 평균 resolution이 482 x 415 라고 한다. 이를 input으로 사용하기 위해 downsample을 하는 과정에서 정보 손실이 발생한다. 이를 줄이기 위해 downsizing 목적의 네트워크를 학습시켜 사용하는 경우도 있지만 추가적인 computation이 발생하므로 효율적이지 못하다. 이 논문에서는 이 문제를 이미지의 DCT를 reshape하여 input으로 사용하는 방식으로 해결하였다. 기존 CNN에 거의 그대로 사용가능하며 이 방법을 적용하여 classification, object detection, segmentation 등등에서 더 좋은 결과를 얻을 수 있었다고 한다.
이 논문에서는 contribution을 5가지를 제시한다.
- 기존 CNN을 약간만 변형시켜 input으로 DCT coefficient를 사용하여 학습했다.
- spatial domain에서 이미지를 preprocessing 했을 때보다 frequency domain에서 preprocess를 하여 이미지 정보를 더 잘 보존했다.
- spectral bias를 조사해서 CNN이 high-frequency channel보다 low-frequency channel에 더 sensitive 하다는 것을 보였다. (이는 human visual system(HVS)과 비슷하다고 한다.)
- tirvial frequency component를 구분할 수 있는 learnable dynamic channel selection method를 만들었다. Infernce에는 static하게 사용한다.
- 이 논문은 object detection과 segmentation에 frequency 정보를 최초로 사용했다고 한다.
Related work
Learning in Frequency domain
기존에 frequency 정보를 CNN에 활용하는 연구에는 CNN 자체를 frequency domain으로 옮기거나 frequency domain에서 featrue를 추출하거나 등등의 방법이 있다. 이 논문은 모델을 frequency domain으로 옮기는 것이 아니기 때문에 더 broad하게 적용가능하다고 하며 network의 spectral bias를 분석하는 방법을 제공한다는 점에서 기존 연구들과 다르다고 한다.
Dynamic Neural Networks
기존 연구들에서는 네트워크를 각 block 단위로 분석하면서 이전 block의 actvation을 활용해 각 block의 각 intermediate input으로 사용하고 이 결과를 분석해 전체 네트워크를 조절하였다. 이 연구에서는 그렇게 이전 block의 output을 활용하지 않고 전체 모델의 raw input을 이용하기 때문에 전체 네트워크의 communication bandwidth를 줄일 수 있었다고 한다.
Efficient Network Training
기존에 network를 efficeint하게 만들려는 연구가 많이 되어왔다. pruning, knowledge distillation, quantization 등등 많은 방법이 있고 FFT-based CNN을 이용하기 위한 연구도 많이 되어왔다. Fourier domain에서 CNN을 적용해 memory나 computation 관점에서 이득을 얻을려는 연구들이다. 하지만 이는 large kernel size에서 주로 이득을 얻을 수 있고 현재 많이 사용되는 3×3이나 1×1 convolution에서는 이득을 많이 보기 어려워 복잡한 optimization 방법들이 필요하다. 이 연구에서는 기존 CNN을 많이 바꾸지 않고 적용 가능하기 때문에 그러한 복잡한 optimization 방법을 적용할 필요가 없고 기본적으로 이 연구는 model complexity를 줄이기보다 input size를 줄이는 쪽에 더 집중하고 있다.
Method
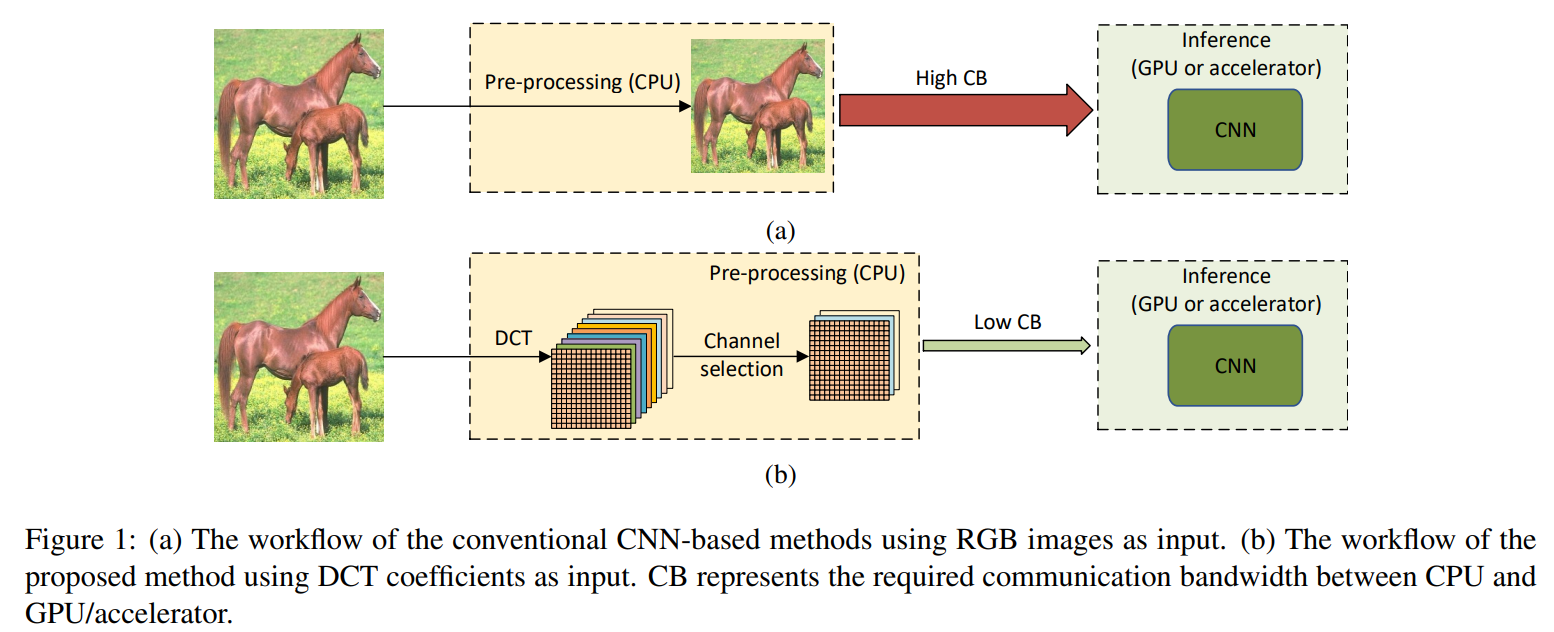
Real-time inference를 위해 대부분 이미지를 CPU에서 preprocess한 후 GPU로 보내서 실행한다고 한다. 이는 CPU와 GPU간의 bandwidth를 줄이기 위함이다. 이 연구에서도 CPU에서 이미지를 preprocess한 후 GPU로 보낸다.
먼저 이미지를 YCbCr color space 로 보낸다 이후 DCT transform을 진행하고 같은 frequency를 가진 component 끼리 묶어 channel을 만들도록 한다. 이 채널중 중요한 채널만 선택해 GPU로 보내줌으로써 CPU/GPU communication bandwidth를 더욱 줄여 inference를 더욱 빠르게 하고 더 높은 정확도를 얻을 수 있었다고 한다.
Data Pre-processing in the Frequency Domain
이제 이 pre-process 방법에 대해 알아보자.
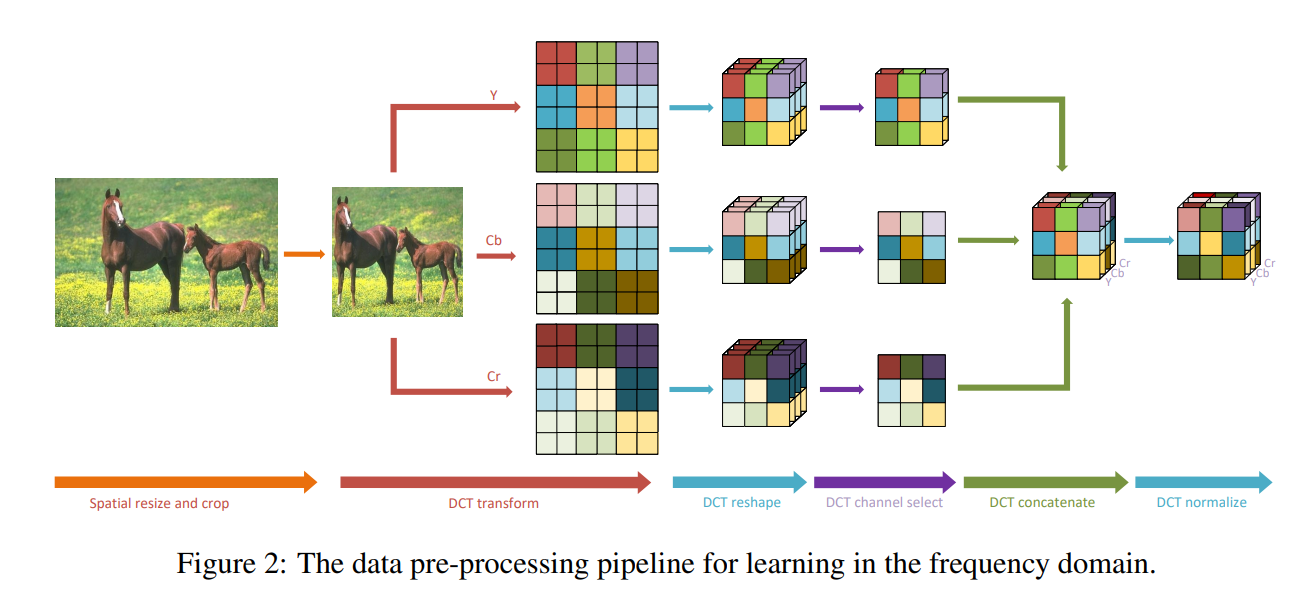
Figure2 그림처럼 먼저 이미지를 resize and crop한다. 이후 이미지를 Y, Cb, Cr로 각각 나누고 각각에서 DCT transform을 진행한다.
일반적인 JPEG compression 방법처럼 이미지를 각각 8×8 사이즈의 patch로 구분하고 각각을 DCT transform 한다. 이 8×8 patch는 각 픽셀별로 특정 frequency에 대한 값을 나타게 된다. 그러고 각 patch의 같은 위치의 픽셀끼리 모아 하나의 채널을 만들게 한다. 그러면 2D 이미지의 H,W는 각각 1/8로 줄어들고 대신 64개의 채널이 생기게 된다. 예를들어 448x448x3의 이미지가 있다고 하면 이는 (448/8)x(448/8)x(3×64), 즉 56x56x192의 사이즈로 변환된다. 각 채널은 같은 frequency의 값끼리 모아놓은 채널이 된다.
Learning based Frequency Channel Selection
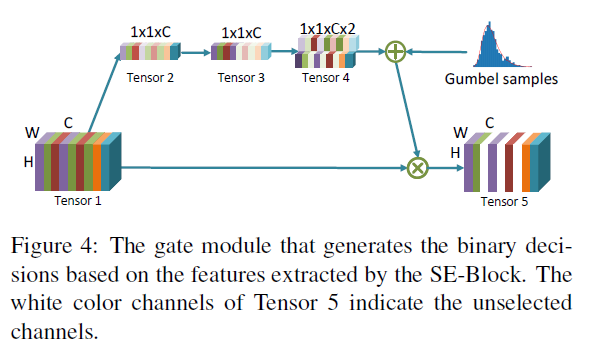
이후 과정은 Figure4에 나와있는대로이다.
preprocess 이후 각 채널별로 특정 frequency 값들이 모아져 있는 텐서가 만들어졌고 이를 average pooling을 통해 1x1xC 형태의 텐서로 만들어 준다. 이후 1×1 convolution을 한번 통과시켜 1x1xC 텐서를 한번더 만든다. 여기까지는 squeeze-and-excitation block이라고 불리는 SE block의 방법고 같고 각 channel간의 관계를 잘 이용할 수 있게 해주는 방법이라고 하며 trivial channel을 suppress하는데 도움을 준다고 한다. 이후 두개의 trainable parpamer를 곱해 1x1xCx2의 텐서를 만들고 각 텐서를 noramlization 해서 각 채널을 선택할 수 있는 확률로 사용할 수 있게 하였다.(각각이 on and off의 확률을 나타낸다. 즉 하나가 7.5, 하나가 2.5면 75%의 확률로 그 채널을 사용한다.)(사실 그러면 1x1xC로도 0~1값만 나오도록 activation을 만들던가 해서 확률로 충분히 사용가능할 것 같은데 굳이 두개를 만들어 on and off 확률을 만들 이유가 있었는지 잘 모르겠다.)
여튼 두 값을 이용해 확률 p를 만들고 베르누이 확률분포대로 0 or 1로 binary decision을 한다. 여기서 binary decision을 할 때 문제가 미분이 불가능하므로 Gumbel Softmax Trick을 사용해 해결한다. 이렇게 각 채널을 선택하는 연산 과정을 gate module이라고 한다. 이 gate module을 F라고 하고 각 채널을 x라고 하면 아래와 같은 식을 만족하면 각 채널을 선택한다.
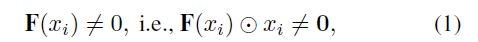
즉 각 채널을 gate module에 넣었을 때 output이 0이 아니어야 하고 gate module을 통해 나온값과 채널을 곱한 결과도 0이 아니면 그 채널을 사용하게 되는 것이다. 각 채널은 특정 frequency를 의미하므로, 이 말은 즉 그 특정 frequency를 input으로 사용한다는 의미이다.
사용하는 채널수가 적을수록 input을 작게 사용할 수 있기 때문에 목표는 최대한 적은 채널을 사용하면서도 정확도를 유지하는 것이다. 따라서 아래와 같은 식으로 전체 loss를 만들게 된다.
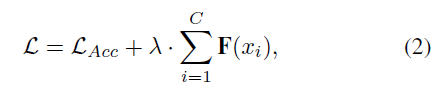
Static Frequency Channel Selection
각 채널이 어떻게 선택되는지 관찰하기 위해 task 별로 freuqency가 선택되는 확률을 관측했다고 한다.

첫번째 줄은 classification, 두번째 줄은 segmentation에 대해서 각 freuqency 별로 어떤 확률로 선택되는지 관찰한 결과이다. 8×8의 DCT결과이므로 왼쪽위로 갈수록 low-freuqency 부분이고 오른쪽 아래로 갈수록 hight-freuqency 부분이다. 일반적으로 low freuqency 부분이 훨씬 많이 사용된다는 것을 알 수 있었고 각 Y, Cb, Cr 부분에서 Y의 high-frequency part가 다른 Cb, Cr 채널보다 많이 선택된다는 것을 알 수 있었다. 또한 classificaiton, segmentation 이 다른 task임에도 불구하고 비슷하게 선택되었다는 것을 알 수 있고 high-level vision task에서 비슷하게 나타날 것이라고 한다. 이는 HVS(human visual system)과도 비슷한 결과이며 human eye가 원하는 바와 CNN이 원하는 바가 비슷함을 알 수 있다고 한다. 즉 lower freuqency part를 많이 선택하고 Y채널인 밝기 부분에서 많은 part를 선택하고 나머지를 pruning함으로써 input을 많이 줄이면서도 정확도나 정보 손실을 최소화 할 수 있다고 한다.
이와 같은 preprocess된 결과를 network에 사용하기 위해 기존 네트워크의 시작부분만 살짝 변형을 해준다.
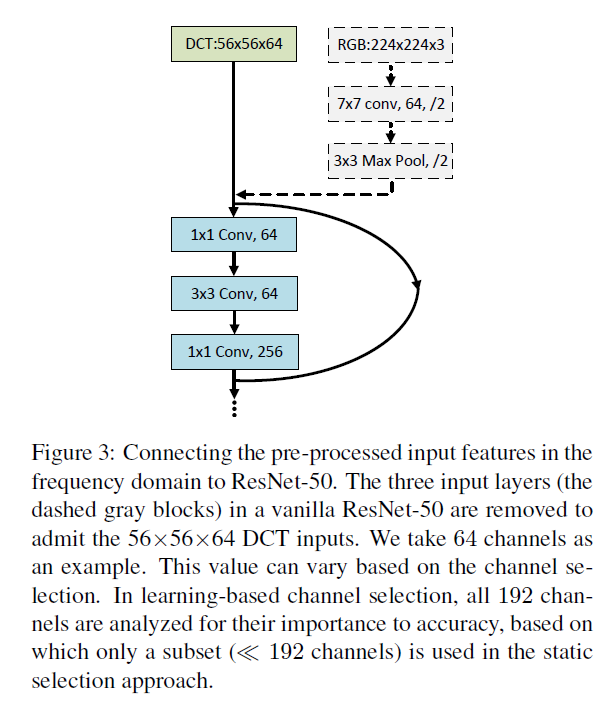
위의 Figure는 ResNet을 가지고 예를 든것이고 위처럼 시작부분만 살짝 변형하면 frequency domain에서 preprocess된 input을 network에 그대로 사용할 수 있다.
Experiment Results
실험은 classification, detection, segmentation 이 3가지로 진행했다.
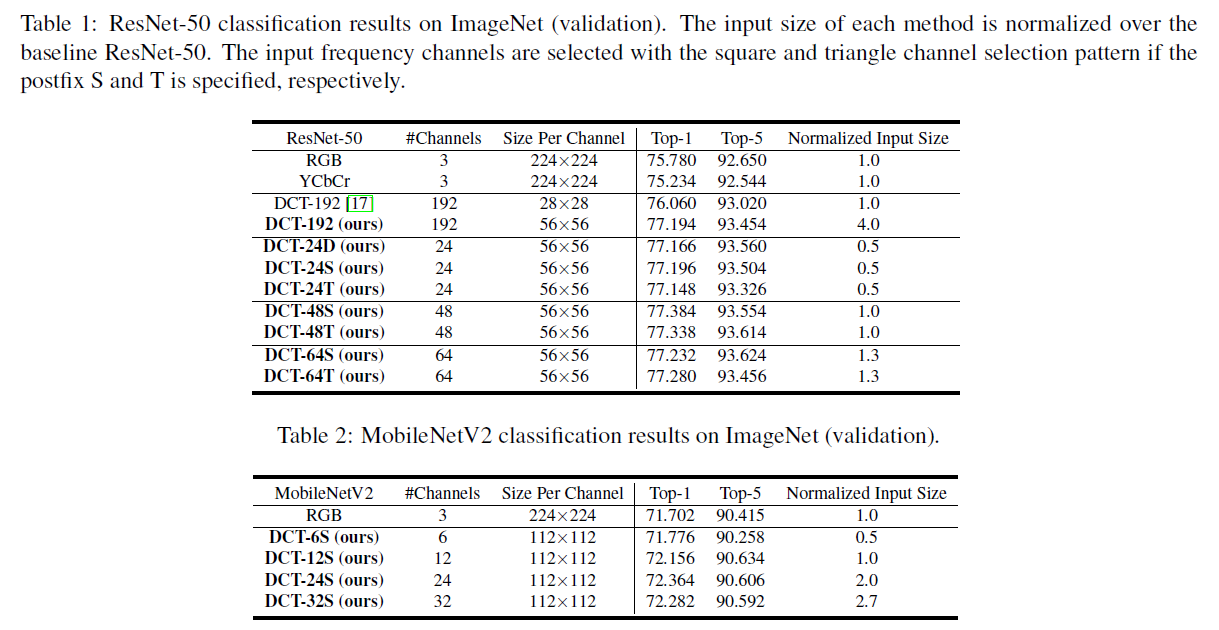
DCT-xxD/S/T에서 xx는 몇개의 채널을 선택했는지이고 D/S/T는 각각 frequency part를 선택할때 위에서 설명한 Dynamic 방식인지 upper left부분의 Square인지 Triangle인지를 의미한다고 한다. DCT-24S에서 원래 input보다 절반 사이즈만 사용하게 되는데도 불구하고 더 높은 정확도를 보인다. 이러한 결과는 CNN은 낮은 frequency의 정보만 가지고도 high-lelvel vision task를 잘 할 수 있고 high-freuqency 정보는 오히려 noise로써 작용할 수 있다는 것을 의미한다고 한다. 실제로 Table1을 보면 192개의 frequency 채널중에 48개를 사용했을 때 가장 정확도가 높게 나오고 192개의 채널을 모두 사용하는 경우 정확도가 더 떨어지는 것을 볼 수 있다.
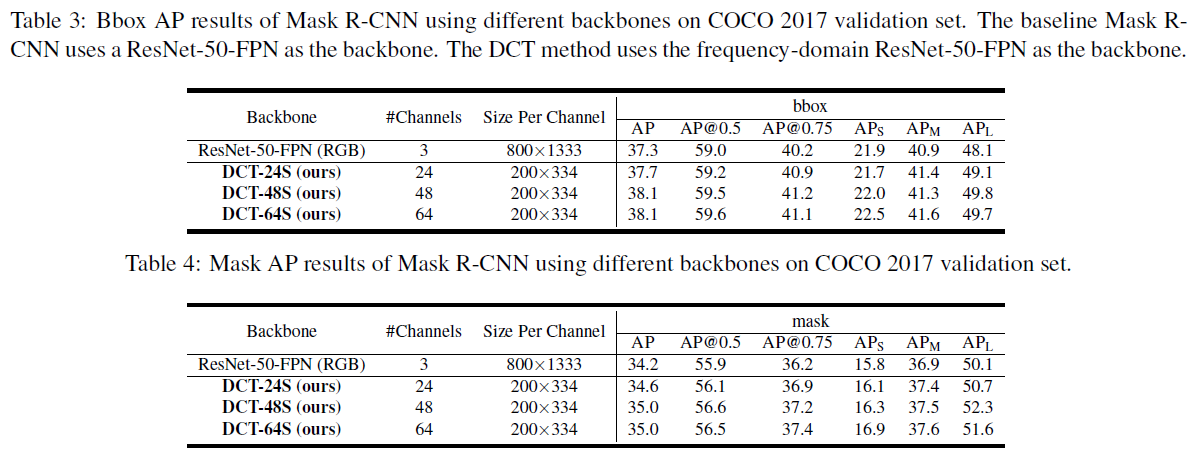
Table 3,4는 각각 object deteciton과 segmentation에 대한 결과이고 classification과 전체적으로 비슷한 결과를 보임을 알 수 있다.
Conclusion
preprocess 단계에서 spatial domain에서 이미지를 downsampling 하는 것보다 frequency domain에서의 정보를 이용하여 downsampling 하면 더 정보손실을 최소화하면서 input size를 더 줄일 수 있다고 한다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.