간단하게 noise2noise와 noise2void 방식을 정리해보려고 한다.
각각 논문 제목은 아래와 같다.
“Noise2Noise: Learning Image Restoration without Clean Data” (2018 ICML)
“Noise2Void – Learning Denoising from Single Noisy Images” (2019 CVPR)
기본적으로 딥러닝을 이용해 Denoising을 학습시킬 때는 아래와 같이 noisy image와 clean image를 이용한다.

이런 noisy와 clean 이미지의 pair를 얻는것이 쉽지 않기 때문에 이런 pair 데이터 없이도 네트워크를 training시키기 위해 n2n, n2v 등의 방식이 등장했다.
먼저 n2n의 training 방식은 아래와 같다.

두개의 noisy image를 이용해 하나를 input 하나를 gt처럼 이용해 training을 하는 것이다. 이렇게 학습을 하면 네트워크가 점점 clean한 이미지를 뽑도록 학습이 된다. 이의 원리는 아래 그림이 잘 나타내준다.
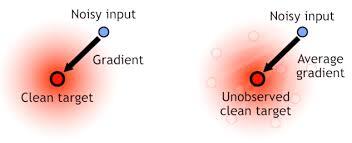
위 오른쪽 그림을 보면 clean target 주위의 여러 noisy 이미지들이 있지만 결국 여러 noisy 이미지들의 평균은 clean 이미지가 된다. 따라서 무작위 noisy 이미지들만 가지고 학습을 해도 clean한 output이 나오도록 네트워크가 학습된다는 이야기이다.
다음은 noise2void의 학습 방식이다. 아래의 figure가 학습방식을 잘 설명해주고 있다. 먼저 전체 이미지인 (a)에서 patch를 뜯어낸다. 이렇게 얻어낸 patch에서 (b)처럼 가운데에 있는 pixel을 patch에 있는 무작위 pixel로 바꿔서 네트워크의 input에 넣는다. 즉, 가운데에 있는 pixel은 원래의 정보를 잃고 blind-spot이 된다. 그리고 output에서 가운데 pixel이 원래 pixel값을 예측할 수 있도록 loss를 걸어 학습시킨다.

위 방식이 작동하는데에는 몇가지 가정이 있다.
1. noise는 구조가 없다.
2. noise를 예측할 수 없다.
따라서 주변 픽셀들만 보고 가운데 픽셀을 예측하라고 하면 noise가 아닌 clean한 이미지의 픽셀을 예측할 것이다.
n2n 방식 같은 경우에는 training도 쉽고 간단하지만 결국 같은 이미지에서 noisy 이미지가 2개씩 필요하기 때문에 2개의 noisy 이미지 pair를 얻어야한다는 단점이 있고
n2v 방식은 noisy 이미지 한장만 가지고 있어도 training을 할 수 있다. 하지만 패치에서 가운데에 있는 픽셀도 그 자체적으로 정보를 가지고 있을 수 있기 때문에 같이 활용해주는게 좋을텐데 아예 blind-spot 으로 사용해버려서 정보를 아예 안쓰기 때문에 결과가 sub-optimal일 수 있다는 단점이 있다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.