Artificial Intelligence: A Modern Approach (4th edition) 기준으로 정리할 예정이다.
Background
MDP (Markov decision processes)
MDP란 순차적으로 행동을 결정해야 하는 문제를 풀기 위해 수학적으로 표현한 것으로 아래와 같이 5가지 tuple로 구성되어 있다.

S : set of states
A : set of actions
P : state transition probability matrix, 특정 시간의 상태(\( S = s_t \))에서 어떤 action(a)을 취했을 때 다른 상태 (\(S = s_{t+1}\))가 될 확률을 나타내는 함수
R : reward function, 특정 시간의 상태(\( S = s_t \))에서 어떤 action(a)을 취했을 때 agent가 받을 보상을 나타내는 함수
\( \gamma \) : discount factor, 가까운 시간에 받는 보상은 영향을 크게, 먼 미래에 받는 보상은 영향을 작게 만드는 역할을 한다.
위의 요소들을 가지고 최종적으로 아래와 같은 기댓값을 최대화 시킬 수 있도록 학습하게 된다.

23.1 Learning from Rewards
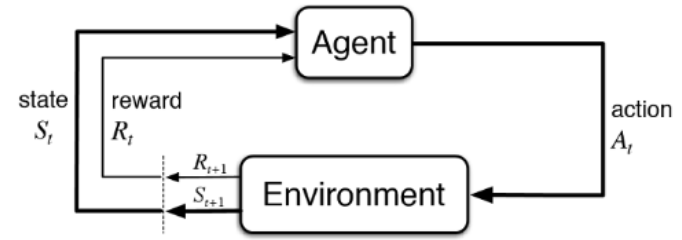
Reinforcement Learning (RL) : Agent interacts with the world and periodically receives rewards that reflect how well it is doing.
Agent는 특정 Policy를 이용해 주어진 state에서 action을 선택하여 Environment에 인가하고 state를 변화시킨다. 그 결과로 reward를 받으며 학습을 하게 된다.
각 학습 케이스에 대한 label이 필요한 supervised learning과 다르게 reinforcement learning에서 reward function은 만들기 훨씬 쉽다는 장점을 갖고 있다. 하지만 강화학습에서도 sparse reward 같은 문제도 존재한다.
Sparse reward : 특정 action을 했을 때 정확한 reward를 주기 어려운 경우 각각의 모든 time step에서의 reward를 주기 어려워 reward의 빈도가 sparse 해지는 케이스. (바둑이나 체스, 레이싱 게임 등)
강화학습에는 수많은 방법이 있지만 크게 두가지 카테고리로 나눌 수 있다.
- Model-based reinforcement learning : Agent가 Environment의 model을 어느 정도 알고 있다고 가정하고 문제를 푸는 것. 위에서 언급한 MDP에서의 P (transition model)를 알고 있다고 가정하는 것이다. agent의 action에 따라 state가 어떻게 바뀔지 예측 가능하기 때문에, 변화를 미리 예상해보고 최적의 action을 planning 하는 것이 가능하다.
- Model-free reinforcement learning : Agent가 Environment의 model을 모르는 상황에서 문제를 푸는 것. 따라서 agent가 environment와 직접 상호작용을 해가면서 학습을 해야한다. Model-free 방식은 두 가지로 구분할 수 있다
- Action-utility learning : 가장 흔한 방식은 Q-function(quality function)을 학습하는 Q-learning으로 quality-function의 highest value를 주어진 state에서 찾는 방식으로 진행된다. ( Q-function은 state와 action를 가지고 reward를 계산해주는 함수 )
- Policy search : 주어진 state에서 action으로 mapping해주는 함수인 policy 함수를 학습한다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.