Introduction
이번 논문은 Transformer를 Image Restoration 분야에 성공적으로 적용시킨 논문이다.
Image Restoration 분야에서 Transformer를 쓰기 힘들었던 이유 중에 하나는 self-attention의 computation 양 때문이었다. 특히 attention이 이미지의 resolution의 제곱에 비례해서 computation이 증가하기 때문에 비교적 큰 resolution을 다루는 restoration 분야 특성상 transformer를 적용하기 더 어려웠다. 이 논문에서는 attention을 조금 변형시켜 spatial dimension에서 적용하지 않고 channel dimension에 적용함으로써 computation이 resolution에 linear하게 비례하도록 만들었다. 따라서 제목도 Efficient Transformer for high resolution image restoration이다.
Method
기본적으로 unet 구조를 가지면서 깊어질수록 많은 Transformer Block들을 가진다. 코드 상 default는 밑의 그림에서 각 Transformer Block 개수인 L1,L2,L3,L4가 각각 4,6,6,8개로 설정되어 있다. 각 Transformer Block은 attention 역할을 하는 MDTA(Multi-Dconv head Transposed Attention), FFN 역할을 하는 GDFN(Gated-Dconv Feed-Forward network)으로 구성되어 있다.
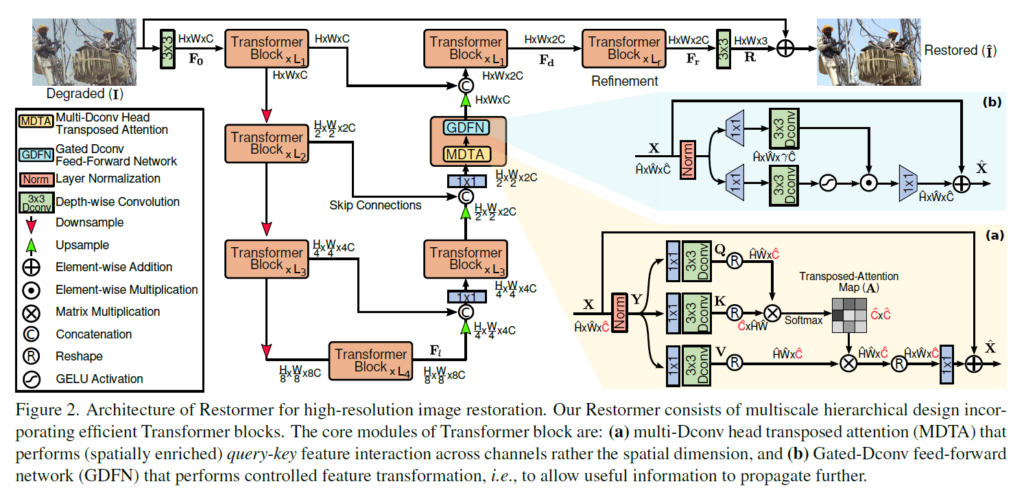
위의 그림에서 (a)와 (b)가 각각 MDTA와 GDFN의 구조인데 이게 어떻게 기존 attention을 변형시킨건지 살펴보자.
MDTA(Multi-Dconv head Transposed Attention)
기본 Transformer에서 attention에 쓰이는 방법은 아래 그림과 같다.
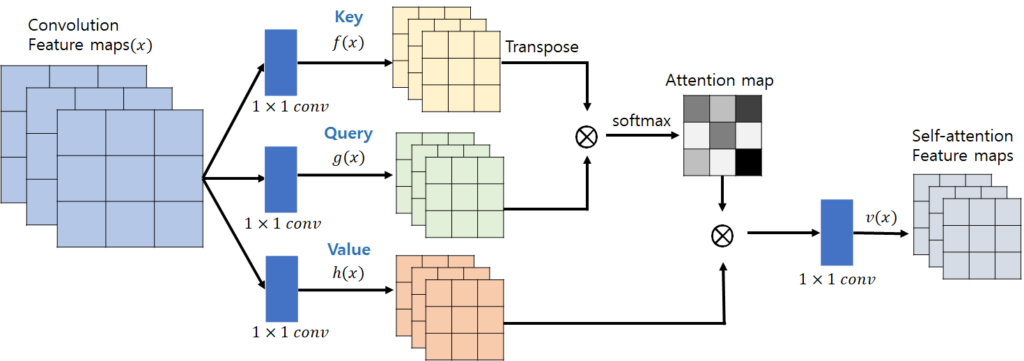
Input을 Query, Key, Value의 3개로 나누고 Query와 Key를 matrix multiplication 해서 attention map을 얻은 후 Value와 matrix multiplication을 해서 최종 output을 얻어낸다. 이는 spatial dimension에서 연산이 되기 때문에 resolution이 커지면 제곱에 비례해서 연산량이 증가한다. 이를 해결하기 위해 patch size를 매우 작게 만들어서 self-attention을 하기도 했는데 patch size가 작아지면 이러한 self-attention의 의미가 희석된다. 이 논문에서는 따라서 spatial dimension에서 attention을 하지 않고 channel dimension에서 attention을 해서 연산량을 줄였다.
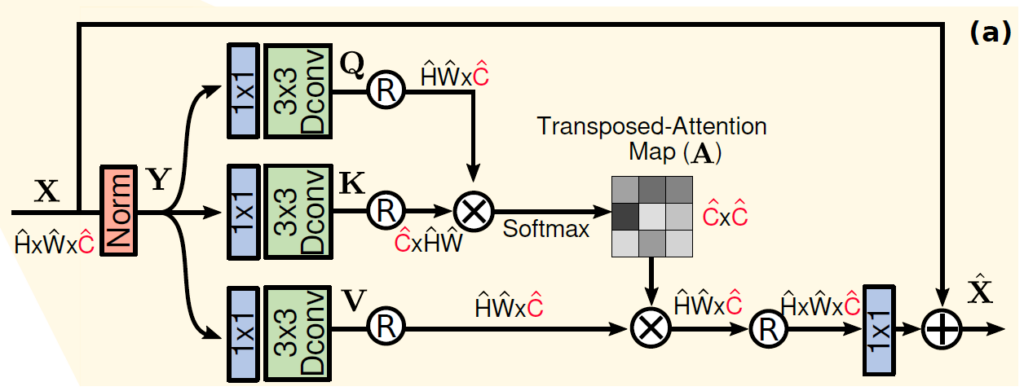
input이 들어오면 layer normalizaion을 한번 해주고 1×1 convolution을 통해 채널을 3배로 늘려준 후 나눠서 각각 Q,K,V를 만들어준다. 거기서 3×3 Depthwise convolution을 해서 최종 Q,K,V를 만들어주고 각각의 matrix를 reshape해서 Query와 Key를 곱했을 때 attention map이 Channel*Channel 의 크기를 갖게 된다. 정확히는 multi head이기 때문에 attention map의 크기는 [Batch, head 개수, C, C]이 된다. 일반적으로 Channel이 H*W 보다 훨씬 작기 때문에 이 연산이 원래 self-attention 보다 연산량이 줄어들게 된다. 이런 방식으로 효율적인 attention을 진행한다.
GDFN(Gated-Dconv Feed-Forward network)
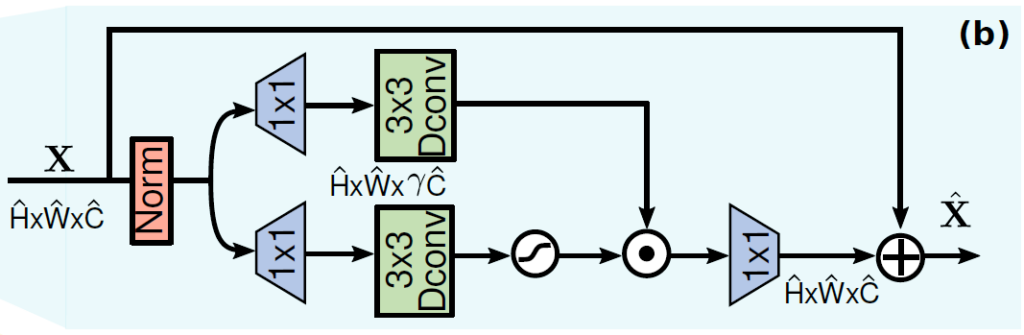
이후 원래 Transformer에서 Feed-Forward 역할을 하는 부분인 GDFN(Gated-Dconv Feed-Forward network) 이 있는데 구조는 아래와 같고 단순하게 input을 1×1 및 depthwise 3×3 convolution으로 나누고 하나는 gelu function으로 통과시키고 element-wise multiplication후 다시 1×1 convolution으로 채널 수를 조절한 뒤 input과 residual sum을 해주고 output으로 내보내준다.
Progressive Learning
추가로 Progressive Learning 방식도 적용했다고 하는데 기본적으로 고정된 patch size를 학습에 계속 이용하게 되면 나중에 test 에서 학습되지 않은 resolution의 이미지가 들어오면 성능하락이 존재한다고 한다. 따라서 학습중에 patch size를 조금씩 증가시켜서 학습시켜서 (대신 batch size를 줄임) 다양한 resolution에 대한 robustness를 증가시키는 방법을 사용했다.
Experiment
Deraining, Deblurring, Denoising 등 다양한 image restoration 분야에 적용해 실험했고 결과가 매우 좋았다.
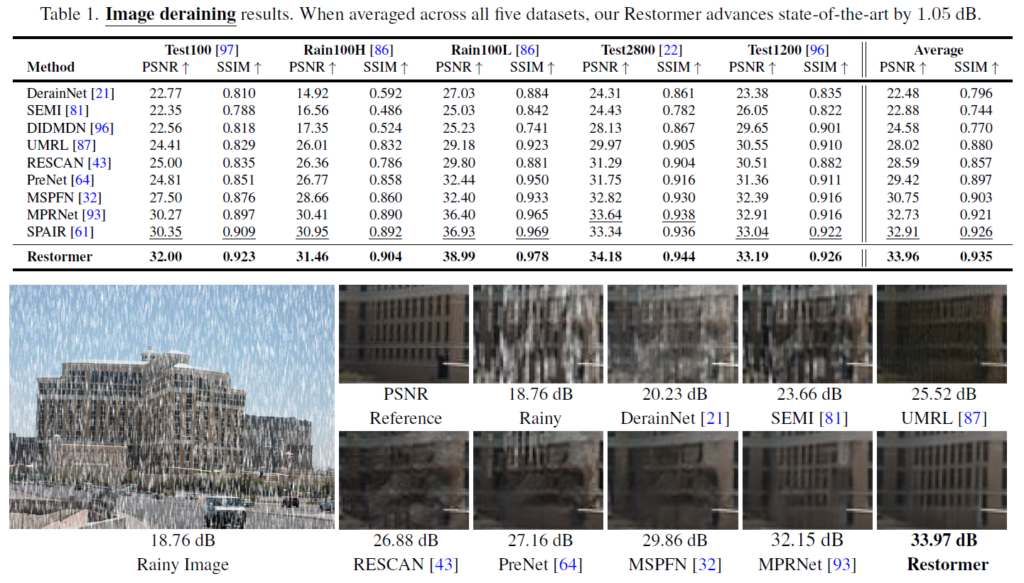
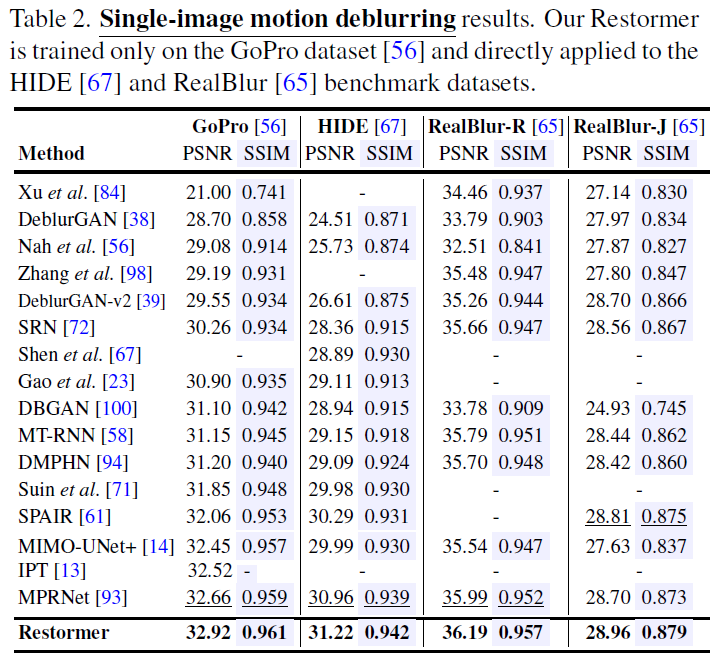

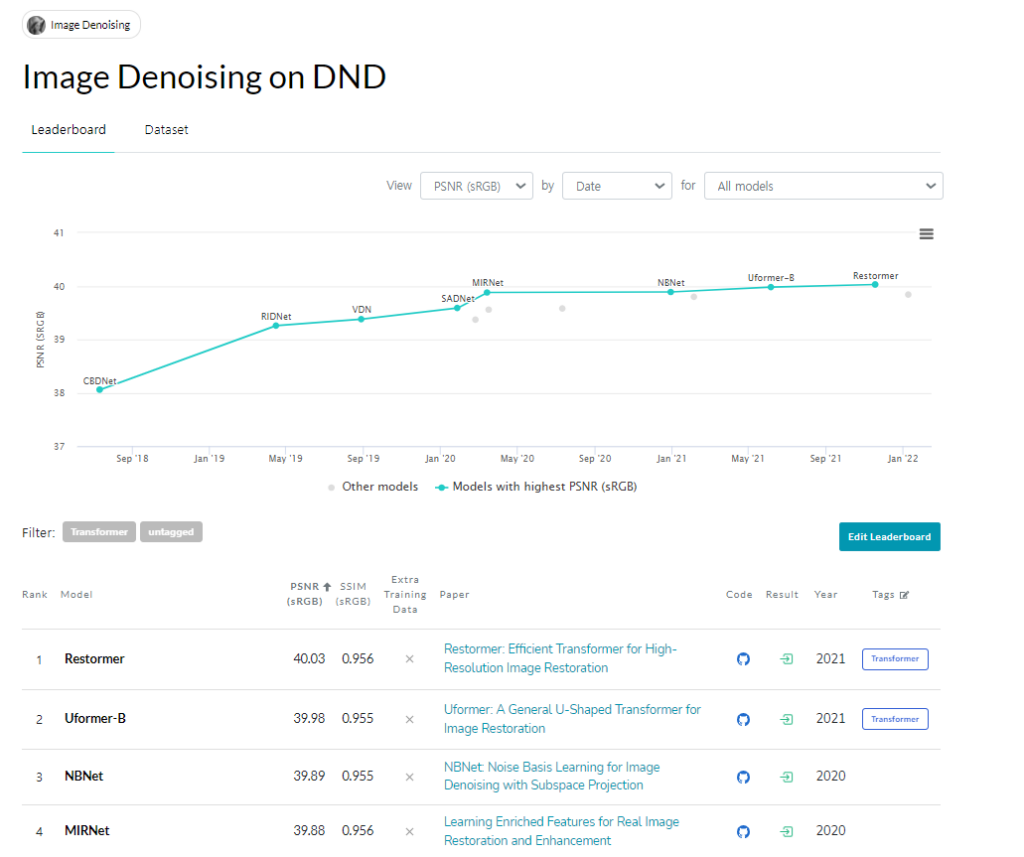
특히 DND benchmark에서는 지금도 SOTA의 성능을 내고 있다. DND 데이터셋 같은 경우에는 denoising dataset인데 training 데이터가 따로 없기 때문에 다른 데이터셋을 이용해서 학습시킨 네트워크를 가지고 DND 데이터셋에 적용해야한다. 따라서 일반적으로 같은 real-noise dataset인 SIDD dataset에서 학습시키고 DND에서 테스트해보는게 일반적인데 이전에 리뷰한 NAFNet 논문같은 경우에는 SIDD에서 학습시키고 DND에서 결과를 확인하면 성능이 많이 떨어지는 것을 볼 수 있다. 하지만 Restormer 같은 경우에는 DND 에서도 비슷하게 좋은 성능을 낸다. 즉, generalization 능력이 더 좋다고 볼 수 있다.
Conclusion
Transformer를 Image Restoration 분야에 적용. 대부분의 분야에서 거의 SOTA의 성능. But 여전히 많은 연산량이 필요함.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.