
SONY 회사에서 나온 2024 ECCV 논문이다. instructpix2pix 논문에서 착안해서 all-in-one image restoration에 적용한 논문이다. instructpix2pix 논문도 리뷰를 포스팅 했었으니 필요하면 참고 (https://doinghun.com/instructpix2pix-learning-to-follow-image-editing-instructions-2023-cvpr/). 기본적으로 all-in-one setting으로 여러 image restoration task들을 하나의 모델만 가지고 학습시키고 human instruction을 통해 각각의 task를 구분하여 실행시키는 방법을 제안한다.
Image Restoration Following Instructions
instruction-based image restoration을 위해 먼저 instruction을 생성한다. GPT4를 통해 생성을 하고 일반인, 사진전문가 등 다양한 사람이 쓸 법한 instruction을 생성한다. 이후 애매하거나 unclear한 instruction은 제거를 했다고 한다 (make the image clearer, improve the image 등). 아래와 같이 생성된 prompt들의 예시가 나와있다.

이렇게 instruction들을 생성해 놓고 training 할 때 특정 degradation에 맞는 instruction을 random으로 가져와 사용한다. inference에서는 사람이 직접 insturciton을 입력하면 그에 맞게 image restoration이 이루어지는 방식이다.

Text Encoder
instruction을 사용하기 때문에 text encoder가 굉장히 핵심적인 부분이 된다.
대부분의 논문에서 많이 사용하는 CLIP의 text encoder 같은 경우에는 visual content와 매칭되도록 학습이 많이 되어있는데 여기서 사용하려는 text encoder는 degradation에 대한 instruction이지 visual content에 대한 text가 아니기 때문에 효율적이지 않다고 판단하여 pure text-based sentence encoder를 사용했다고 한다 (BGE-micro-v2). 이제 restoration task에 맞게 fine-tuning을 해야 하는데 training할 task가 굉장히 한정적이고 data가 많이 없기 때문에 text encoder 전체를 finetuning하는것은 overfitting을 유발한다. 따라서 text encoder는 freeze하고 뒷 단에 projection head만 추가하여 추가로 학습시켰고 잘 작동했다고 한다. 식으로 표현하면 아래와 같다.
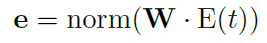
\(E\)는 text encoder, W는 projection head로 단순 fc layer, norm은 l2 norm이다. 이렇게 text encdoer를 만들고 학습 시키게 된다.
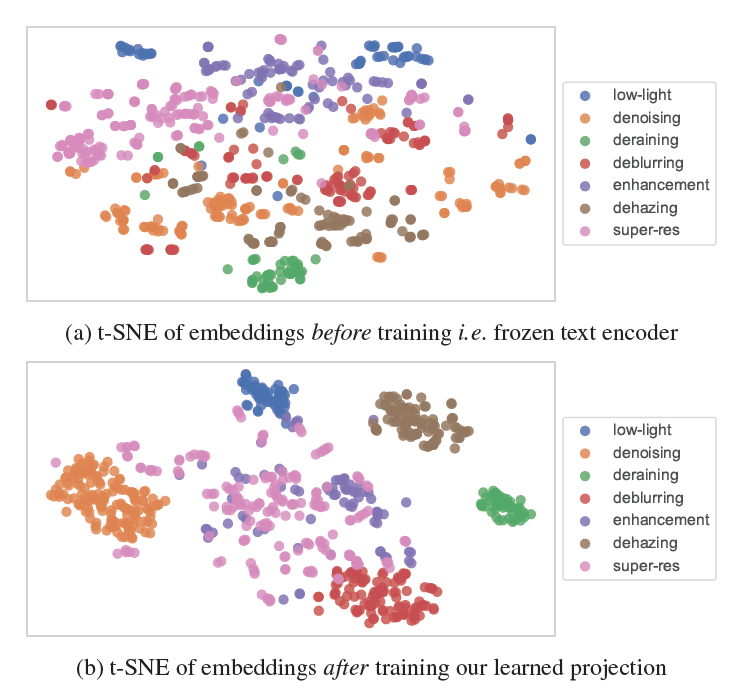
위에는 freeze text encoder만 썼을 때, 아래는 projection head까지 학습시켰을 때 embedding의 t-sne 모습이다. 확실히 clustering이 잘 된 모습이고 super-resolution, enhancement 같은 경우에는 instrunciton이 ‘add detail’ 등으로 애매하게 나올 수 있는데 따라서 denoising, deblurring에 까지 embedding이 섞여 있는 모습이 text logic과 굉장히 닮게 잘 나왔다고 한다. embedding을 잘 분류하기 위해 simple 2 layer mlp로 classification layer를 달아서 embedding을 분류하도록 classification loss를 추가로 사용하여 학습하였다.
InstructIR
Network는 NAFNet을 이용한다. NAFNet도 이전에 포스팅한적이 있으니 필요하면 참고바람.(https://doinghun.com/simple-baselines-for-image-restoration/).
NAFNet에 중간 feature들과 embedding을 섞어 task routing을 해준다. feature와 embedding이 섞이는 과정은 아래와 같다.
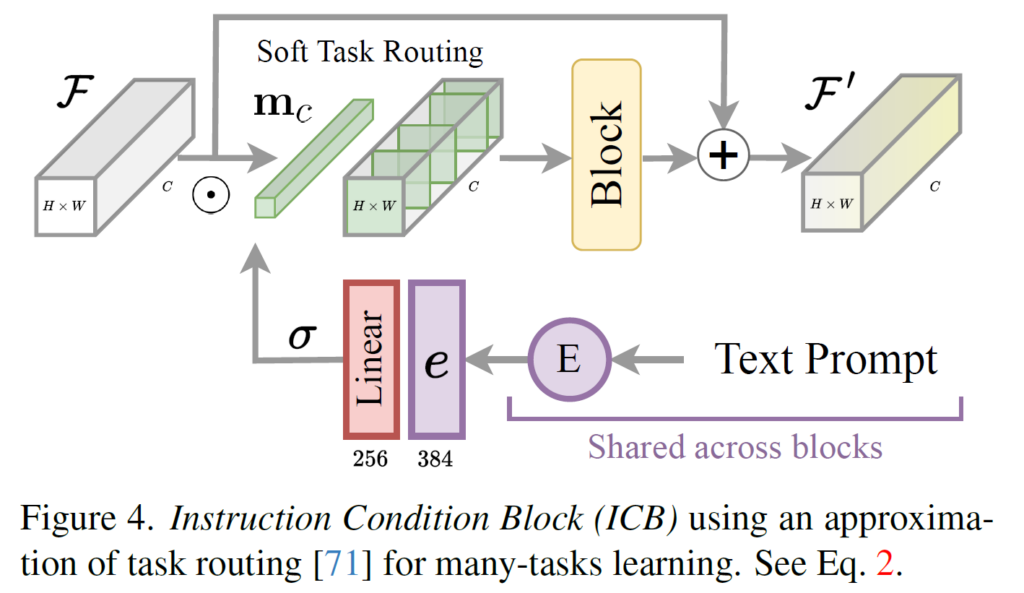
Embedding이 얻어지면 linear layer를 통해 channel 사이즈를 feature channel size와 맞게 만들어주고 sigmoid를 적용, 0~1사이의 값으로 만들어 일종의 soft mask로 만들고 feature에 곱하여 적용한다. 이렇게 얻어진 feature는 text 정보로 인해 특정 task에 필요한 channel들이 많이 활성화되도록 작동하게 된다. 이후 일반 NAFNet block에 한번 넣고 원래 feature와 더하여 최종 feature를 얻는다. 식으로 표현하면 아래와 같다.
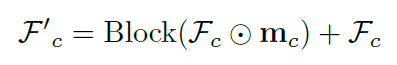
, \(m_c=\sigma(W_c \cdot e )\).
Implementation Details
task는 기본적으로 Deraining, Dehazing, Denoising, Deblurring, Low-light Enhancement 5개의 task로 시작한다. 이렇게 학습시킨것이 InstructIR-5D이고 이후 추가적으로 super-resolution도 추가해 finetuning을 진행하여 task를 6개로 늘려 InstructIR-6D, 한번 더 image enhancement도 추가해서 InstructIR-7D까지 학습시켜 결과를 아래와 같이 비교해놓았다. 아래에 보면 결과가 나와있다.
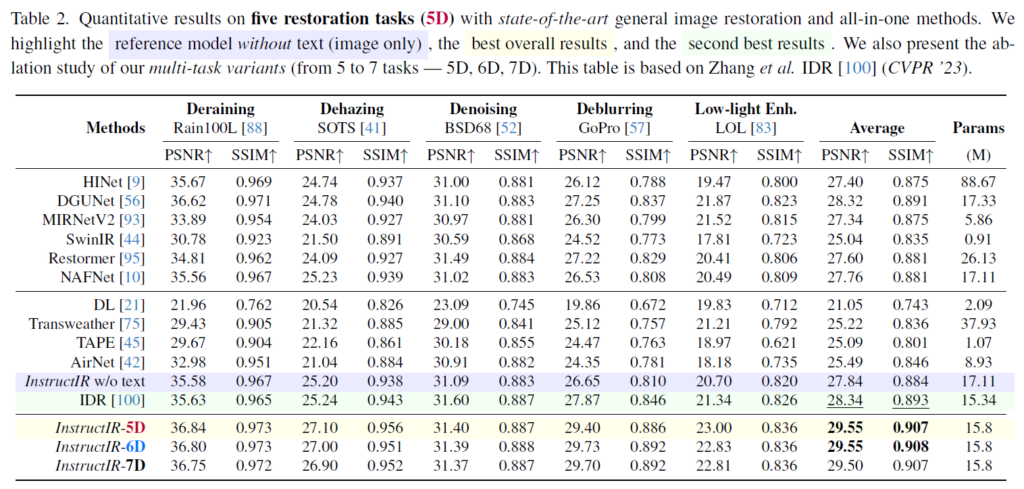
Instruction없이 이미지만 사용했을 때보다 instruction을 사용하면 성능이 대략 1.71dB 정도 평균 성능이 상승한다. 꽤나 큰 폭이다. 또한 이전 work들에 비해서도 최소 1dB 이상 상승했다. 또한 5D에서 6D, 7D로 늘려갈 때 average성능을 보면 super resolution을 추가해도 성능이 거의 떨어지지 않았고 enhancement까지 추가했을 때 다른 task들에서 약간의 성능 하락이 있었다.
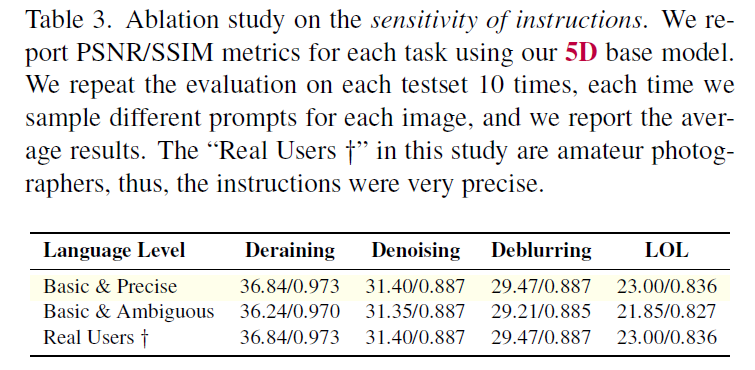
또한 text instruction을 사용하기 때문에 instruction이 애매한지 정확한지에 따라서도 영향을 받을 수 있는데 아래와 같이 ambiguious한 insturciton을 사용하면 성능이 약간 감소하는것을 확인할 수 있다. 하지만 real user에게 시켰을 때 모두 굉장히 정확하게 instruction을 사용했다고 한다.
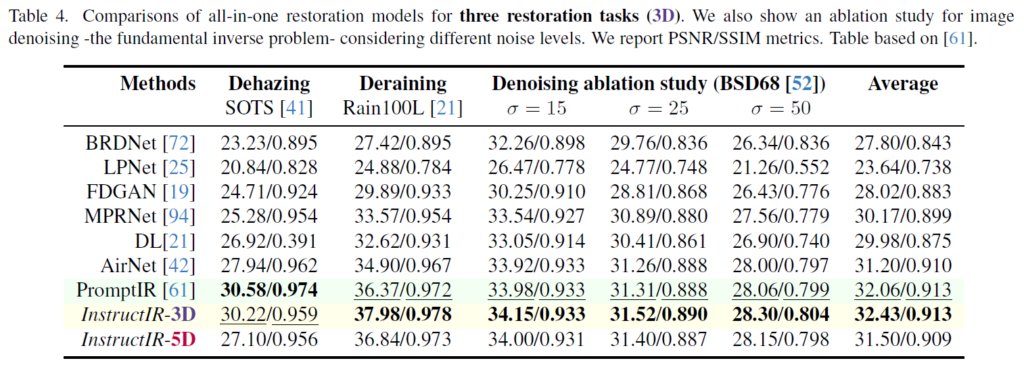
Task를 Dehazing, Deraining, Denoising 3개만 사용해서 학습했을 때에도 아래와 같이 이전 work들보다 좋은 성능이 나온다.
Multi-Task Ablation Study
Denoising을 하려고 해도 그에 맞는 instruction이 아니면 작동을 하지 않는 모습이다.

여러 Degradation이 섞인 상황에서도 instruction을 이용하여 하나 씩 restoration을 적용할 수도 있다. (아래 figure에서는 deblurring은 왜 적용 안 했는지 모르겠는데 아마 잘 작동을 안 한 것 아닐까…?)

또한 아래와 같이 다양한 instruction에도 모두 잘 작동한다고 한다. 두번째 줄 같은 경우에는 ‘retouch it as a photographer’, ‘can you remove the raindrops?’ 등 약간은 애매할 수 있는 insturciton이 사용되어도 원래 결과와 동일하게 작동한다고 한다. 그런데 사실 이미지를 좀 더 자세히 보면 ‘can you remove the raindrops? 라고 instruction을 준 경우에는 비 자국이 미묘하게 남아있는 느낌이 드는 것 같다.

이 외에도 다양한 qualitative와 quantitative결과가 있는데 궁금하면 직접 논문을 찾아 읽으면 될 것 같다.
Discussion & Limitation
InstructPix2Pix 방법도 결국 image editing이기 때문에 restoration에도 직접 적용을 해볼 수 있는데 잘 작동하지 않았다고 한다. 즉, restoration을 위한 fine-tuning이 반드시 필요하다는 것이다. 또한 limitation으로는 기존의 diffusion으로 restoration을 하는 work들보다 perceptual quality가 약간은 떨어진다고 한다. 또한 degradation이 여러개 있는 경우 잘 작동하지 않고(ex. real-world image) 학습시킨 degradation에 대해서만 성능 체크를 했으며 학습시 보지 못한 degradation에 대해서는 작동을 못한다는 limitation또한 존재한다. 마지막으로 이러한 limitation들은 realisitic한 dataset이 더 많아지면 해결될것이라고 한다.
Conclusion
instruction을 이용한 image restoration으로 all-in-one setting에서 sota 성능
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.