이미지의 퀄리티를 평가하기 위한 metric들을 정리해보고자 한다. metric들은 아래와 같고 비교하는 대상(ground truth)이 있느냐 없느냐로 reference based metric / non-reference metric으로 구분하였다.
reference based metric
- PSNR (Peak signal-to-noise ratio)
- SSIM (Structural Similarity Index Measure)
- LPIPS
non-ference metric
- MUSIQ
- MANIQA
- LIQE
Reference Based Metric
PSNR
이미지 퀄리티를 평가할때 가장 많이 쓰이는 metric 이다. 주어진 이미지와 reference 이미지의 각 픽셀값의 차이의 제곱을 평균을 측정하는 MSE를 기반으로 측정하는 방법이다. MSE공식은 아래와 같다.
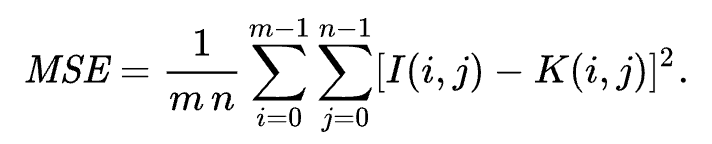
이를 기반으로 한 PSNR공식은 아래와 같다. MAX는 이미지의 픽셀이 가질 수 있는 최댓값으로 8bit 이미지면 255, 0~1의 float로 표현된 이미지면 1을 사용한다.
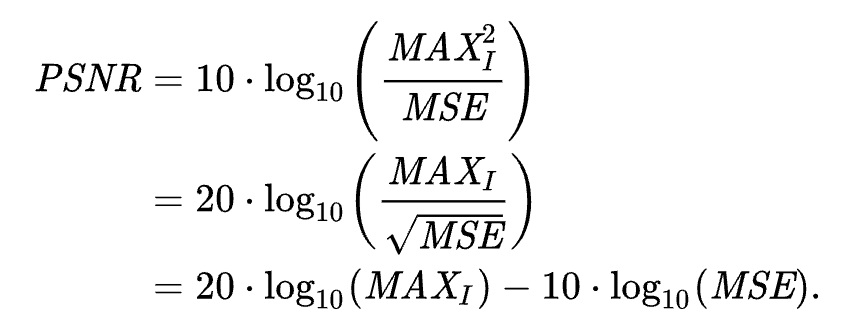
MSE가 분모에 있는 형태이기 때문에 PSNR은 값이 클수록 퀄리티가 좋은 이미지이다.
SSIM
딱딱한 PSNR보다 조금 더 perceptual한 부분을 평가하고자 생긴 metric이다. 이미지의 밝기(luminance), 대조(contrast), 구조(structure)를 측정해 비교하도록 되어있다.
먼저 luminance를 측정하기 위한 방법은 아래와 같고 두 이미지 x,y에 대해서 픽셀값의 평균을 측정하여 \( \mu \)로 표현하여 아래와 같이 사용한다. (픽셀값의 평균이니까 이 값이 밝기를 의미하게 된다)
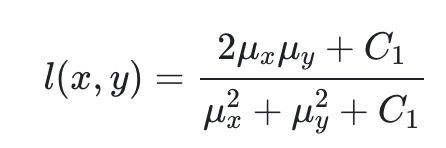
다음은 contrast를 측정하기 위한 식으로 contrast는 이미지 픽셀값의 표준편차를 측정하여 위의 luminance를 구하는 식과 마찬가지로 아래와 같이 만들어 사용한다.
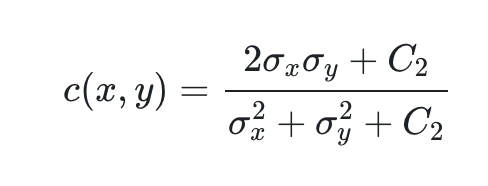
마지막으로 structure를 측정하기 위한 방법인데, 두 이미지의 correlation을 측정한다. 위에서 측정했던 평균과 표준편차를 이용하고 correlation을 추가로 측정해 아래와 같이 사용한다.
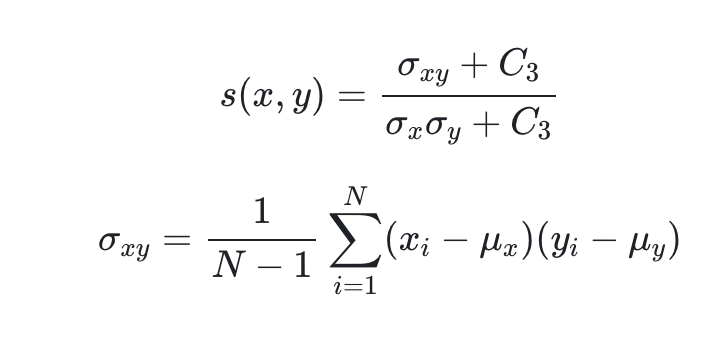
최종적으로 위의 식들을 모두 곱하여 사용하고 아래와 같이 정리가 된다.
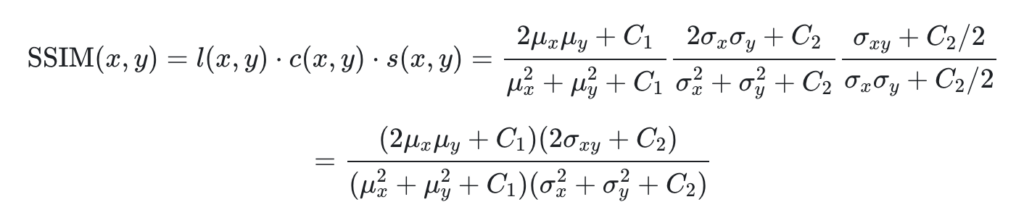
여기에 실제로 SSIM을 측정할때는 이미지에 N*N window를 적용해서 local지역의 mean, std를 각각 구하게 만들어서 계산한다. 이미지의 local한 왜곡을 더 잘 반영하기 위함이다.
LPIPS
“The Unreasonable Effectiveness of Deep Features as a Perceptual Metric” paper에서 소개된 metric이다.

위의 PSNR과 SSIM에 비해 더 perceptual한 부분을 평가할 수 있는 metric이다. 두 이미지를 각각 딥러닝 네트워크에 넣어 feature를 얻어내어 L2 distance를 계산한다. 이때 네트워크는 SqueezeNet, VGG, Alexnet 등 다양하게 쓸수 있고 classification 용으로 학습된 네트워크들인데 이 네트워크들의 중간 feature의 유사도가 사람이 느끼는 두 이미지간의 perceptual한 유사도와 비슷하다는 이야기이다. psnr과 ssim과 같이 reference 가 있을 때 사용하는 metric으로 굉장히 많이 쓰이고 있다.
Non-reference metric
MUSIQ
“MUSIQ: Multi-scale Image Quality Transformer“(ICCV 2021) paper에서 소개된 metric이다.
transformer를 이용해서 이미지의 퀄리티를 평가한다. 아래 그림처럼 이미지를 패치단위로 자르는데 비율을 유지하면서 다양하게 resize를 해서 패치를 가져온다. 패치의 spaital 위치를 기반으로 embedding을 얻고, scale을 기반으로도 embedding을 얻어서 합쳐 사용한다. 그리고 CLS토큰을 넣어 transformer encdoer에 집어넣고 해당하는 output에 학습된 MLP를 태워 최종 quality score를 얻는다. multi-scale image representation을 여러 embedding과 잘 활용하여 이미지 퀄리티를 잘 평가할수 있다고 주장한다. 기본적으로 네트워크를 학습시키는데 사람이 직접 이미지 퀄리티를 평가해 labeling한 데이터(mean opinion score(MOS))셋을 이용해 학습을 시킨다.

MANIQA
“MANIQA: Multi-dimension Attention Network for No-Reference Image Quality Assessment“(CVPR 2022 workshop) paper에서 소개된 방법이고 아래 그림처럼 이미지를 패치단위로 자른뒤 Vision Transformer를 이용해서 feature map을 얻은뒤 attention block, convolution, swin transformer에 태워서 최종 score를 얻어낸다. MUSIQ방법과 마찬가지로 이를 위한 네트워크를 학습을 시키는건데 사람들이 평가해서 labeling 해놓은 데이터셋으로 학습을 시킨다.
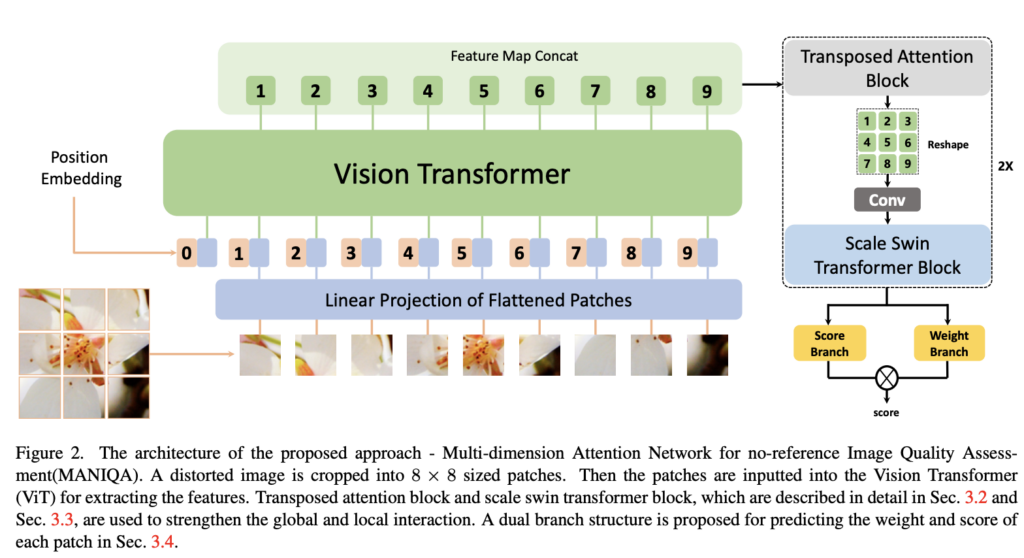
LIQE
“Blind Image Quality Assessment via Vision-Language Correspondence: A Multitask Learning Perspective” (CVPR2023) paper에서 소개된 방식이다.
기본적으로 이미지와 미리 정해져있는 textual templates를 입력으로 받아, 각각 embedding을 얻어내고 cosine similarity, softmax, marginalization을 해서 quality score를 얻어내는 방식이다. textual template을 보면
“a photo of a(n) {s} with {d} artifacts, which is of {c} quality.”
이렇게 되어있는데 s,d,c에 각각 9, 11, 5 가지의 단어가 정해져있다.
s는 scene으로 “animal”, “cityscape”, “human”, “indoor scene”, “landscape”, “night scene”, “plant”, “still-life”, and “others”
d는 distortion type을 “blur”, “color-related”, “contrast”, “JPEG compression”, “JPEG2000 compression”, “noise”, “over-exposure”, “quantization”, “under-exposure”, “spatially-localized”, and “others”
c는 quality score로 1,2,3,4,5 로 이루어져있다.
따라서 총 9*11*5=495 개의 textual template이 같이 입력으로 들어간다. 이 embedding들과 이미지의 embedding을 비교해 최종 score를 얻어내는 것이다.
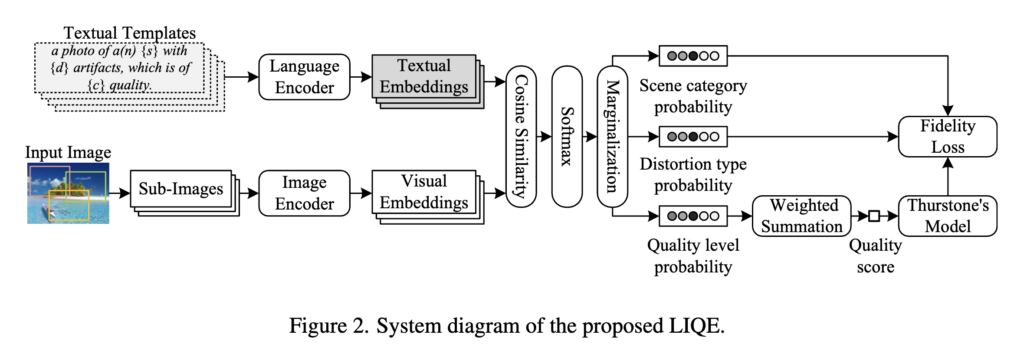
이를 학습시키기 위해 multitask를 만들어 내는데 scene, distortion type도 각각 marginalization해서 구별해내게 학습을 시킨다. 그렇게 해서 이미지와 텍스트 임베딩을 더 잘 연결시킬 수 있다고 한다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.