이번에 리뷰할 논문은 2025 NeurIPS에 발표된 “Instant Video Models: Universal Adapters for Stabilizing Image-Based Networks” 이라는 논문이다. 이 논문은 이미지 기반으로 학습된 딥러닝 모델을 이용해서 비디오에서 추론을 할때 어떻게 안정화(Stabilization)을 시킬 수 있는지 연구한 논문이다. 특히 입력 비디오에 노이즈같은 시간에 따라 변화하는 degradation이 존재하면 이를 복원하는 이미지 기반 모델을 그대로 적용할때 프레임 하나하나는 잘 복원된것처럼 보여도 비디오로 적용해서 보면 결과에 flickering이 존재한다. 아래 비디오에서 unstabilized는 이미지 기반 모델을 그대로 적용한것이고 stabilized는 이 논문의 방법을 적용했을 때 결과이다.
Introduction
비디오를 다룰때 흔하게 다루는 방식은 frame-wise로 다루는 방식이다. 쉽게 말해서 아래처럼 이미지 한장 한장 처리하는 식으로 한다는 얘기이다.
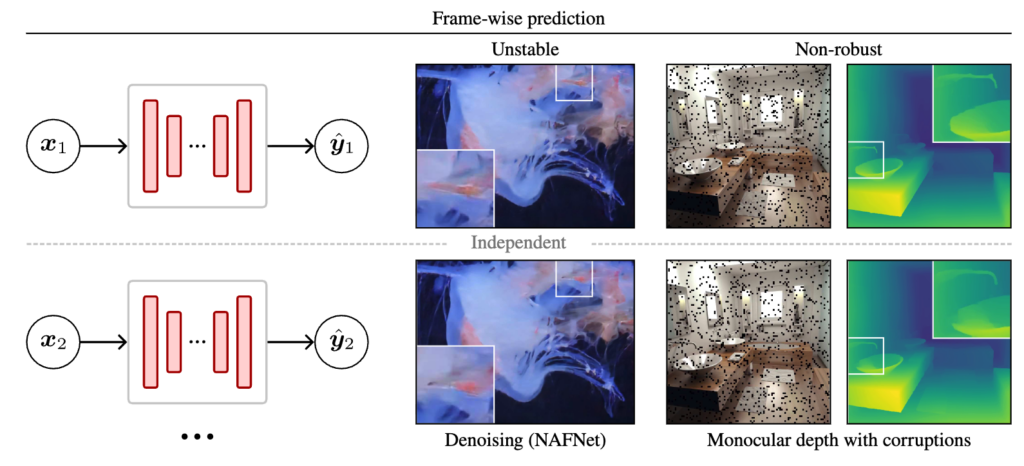
이렇게 하는 이유는 여러가지 이유가 있는데
- 이미지 데이터가 비디오보다 훨씬 다양하고 접근이 쉽기 때문에 학습 데이터를 만들기가 훨씬 용이하다.
- 이미지 모델이 computation과 memory관점에서 비디오 모델보다 작다.
- single frame performance가 증가하는것이 결국에 비디오 기반 task의 성능도 올리는데 기여를 한다.
하지만 이렇게 frame-wise로 비디오를 다룰때 생기는 문제는 temporal consistency이다. 위의 예시 비디오에서 발생하는 깜빡임(flickering)이 대표적인 예시이다. 이는 비디오 전체의 perceptual quality를 떨어뜨릴뿐만 아니라 이외의 다양한 downstream task의 성능저하도 발생시킬수 있다 (ex. 자율 주행에서의 depth estimation을 통한 충돌방지 시스템에서의 불규칙한 동작에 의한 에러). 따라서 이러한 temporal consistency를 잡는것이 매우 중요한 과제이다.
또한 temporal consistency는 corruption robustness와도 연관이 되는데 우리가 카메라를 통한 vision system을 real-world에서 이용할때는 특정 상황에서는 나쁜 기상환경, sensor artifact, low-light 등의 adversarial한 상황에 처할수 있다. 이러한 상황이 잠깐 발생했다 없어지거나 하는 경우가 있는데 단순 이미지 기반으로 이를 처리하려면 매우 어렵지만 만약 근처 frame을 활용할 수 있다면 이를 매우 쉽게 해결할수도 있다. 따라서 이 논문에서는 이러한 예상치 못한 corruption을 일종의 temporal consistency의 연장으로 보고 실험을 진행한다.
사실 당연히 이러한 비디오 모델을 specific하게 만들려는 시도는 매우 많이 있었다. 하지만 이러한 시도들의 한계는 특정 task에 한정해서 모델을 설계하고 대규모 비디오 학습 데이터가 필요하다는 것이다. 따라서 이러한 모델같은 경우 이미지에서 잘 학습된 모델을 재활용하거나 통합시키는데 한계가 있고 추가로 robustness에 대한 고려도 없다.
이 논문에서는 따라서 특정 task에 specific하게 모델을 설계하거나 하는것이 아니라 기존 이미지 기반 모델을 잘 활용하돼 아래처럼 가벼운 stabilizer를 추가해 temporal consistency와 robustness를 증가시킬수 있는 방법을 연구했다.
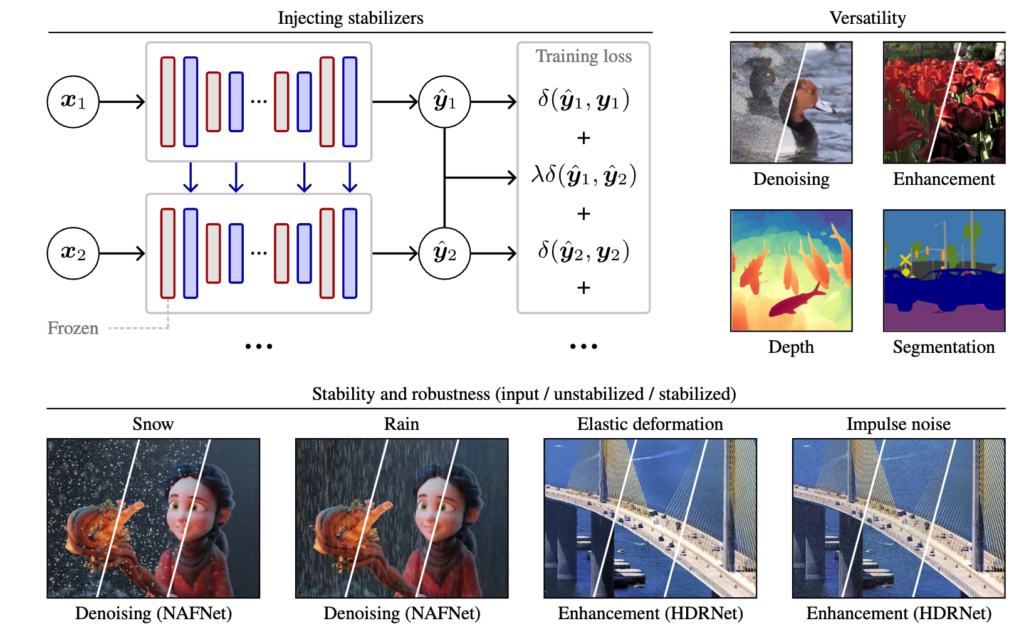
이 논문에서 주로 다룬 내용은 또 accuraccy-stability trade-off 관련된 내용인데 각 stability를 증가시키려고 하다보면 frame별로 모두 비슷하게 만들어 버리는 over-smoothing 현상이 나타난다. 그러면 각 frame별로 accuraccy는 떨어지게 되기 때문에 trade-off가 발생하는데 이 논문에서는 이를 피하기 위한 이론적인 분석도 제공한다.
이 논문에서 제안하는 방법의 장점은 아래와 같다.
- stabilization adapter가 매우 가볍고 modular형식이기 때문에 기존 모델의 파라미터를 추가로 학습시킬 필요없다.
- casualy 동작한다 (현재와 이전 프레임만 보고 동작하기 때문에 streaming환경같은 real-time에서 동작시키기 유리하다)
- low-level과 high-level task에서 모두 적용가능한 방식이다.
이러한 연구를 denoising, image enhancement, monocular depth estimation, semantic segmentaiton에서 실험을 해 결과를 보여준다.
Defining Stability and Robustness
먼저 Stability, \(S\)를 정의하는 방법은 아래와 같다.
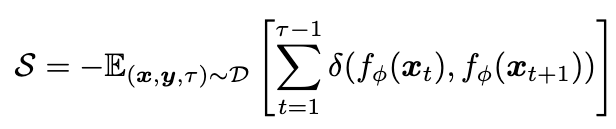
\(x_t\)는 t시간의 input 비디오 프레임이고, \(f_\phi\)는 frame-wise 모델, \(\delta(y_1, y_2)\)는 \(y_1, y_2\)의 거리를 재는 metric이다. 즉 위 식은 t=1부터 \( \tau \)까지의 프레임을 모델에 input으로 넣었을 때 output들이 얼마나 유사한가를 재는 것이라고 보면 된다. 앞에 -가 붙은 이유는 Stability이기 때문에 거리가 작을수록 Stability가 커져야 되기 때문이다.
다음으로 Robustness, \(R_c\)를 정의하는 방법은 아래와 같다.
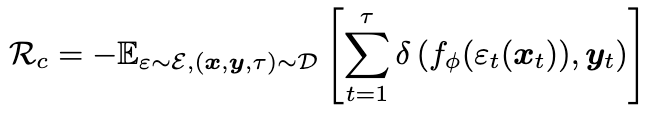
Stability와 다른것은 input에 perturbation을 주는 \(\epsilon_t\)이 들어간다는 것인데, 이렇게 perturbation이 들어왔을때의 ouptut이 원래 target, \(y_t\)와 얼마나 유사한지를 보는것이다.
위 개념이 조합돼서 corruption stability, \(S_c\)를 정의하면 아래와 같다.
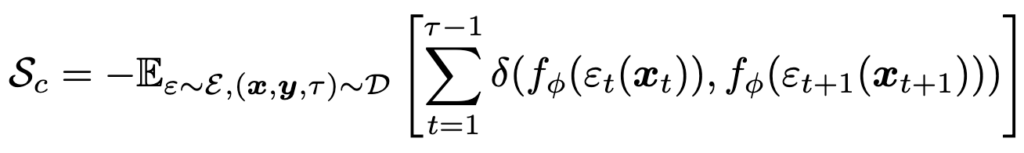
이 논문에서는 \(R_c\)와 \(S_c\)를 이용해 loss를 정의하고 학습에 사용하는데 모델의 최종 output에만 적용하는게 아니라 feature map에도 적용이 된다.
Learning to Balance Stability and Robustness
따라서 Unified accuracy-stability-robustness loss를 아래와 같이 정의한다.
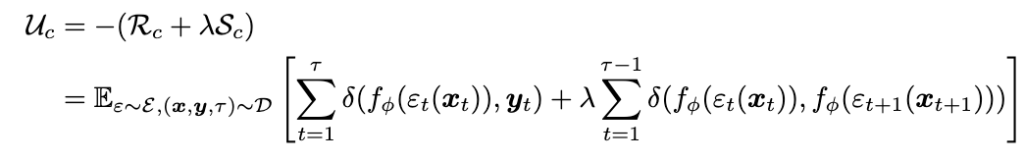
위 식을 보면 \(\lambda\)를 통해서 robust와 stability를 조절하는데 이 \(\lambda\)값을 어떻게 설정해야하는지와 관련하여 theoretical anlysis를 제공한다. 증명은 패스하고 결론만 이야기하면 \(\lambda\)가 일정 값(논문에서는 0.5) 이하면 loss의 최솟값은 각 output이 target과 정확히 일치할 때가 나오고, \(\lambda\) 값이 일정 값 이상이면 그냥 비디오에서 time에 관계없이 그냥 모두 같은 output이 나오는게 loss의 최솟값이 된다. 따라서 첫번째 경우를 oracle bound 두번째를 collapse bound라고 하는데 oracle bound 안에 \(\lambda\)가 존재하면 output은 target과 항상 일치하려고 하고 collapse bound에서는 over-smoothing현상이 나타나서 target에 맞추기보단 계속 이전과 유사한 output이 나오는데에 집중하게 된다.
아래 그림은 이를 표현한건데, \(x_1, x_2, x_3\)가 입력으로 들어왔고 \(y_1, y_2, y_3\)가 target이여서 이를 맞춰야 하는데, \(x_1\)에 대한 output은 \(\hat{y}_1\)으로 이미 얻어져있고 이때 \(x_2, x_3\)에 대해서 output값을 냈을때의 loss가 최소가 되는 지점을 찾은 것이다. 보면 \(\lambda\)가 0과 0.4일때는 \(y_2\)와 \(y_3\)에 대한 예측이 정확히 일치할때 가장 loss가 작다. 반면 \(\lambda\)값이 4일때는 그냥 전부 \(y_1\)으로 예측할때가 최소 loss이기 때문에 학습이 제대로 되지 않는다.
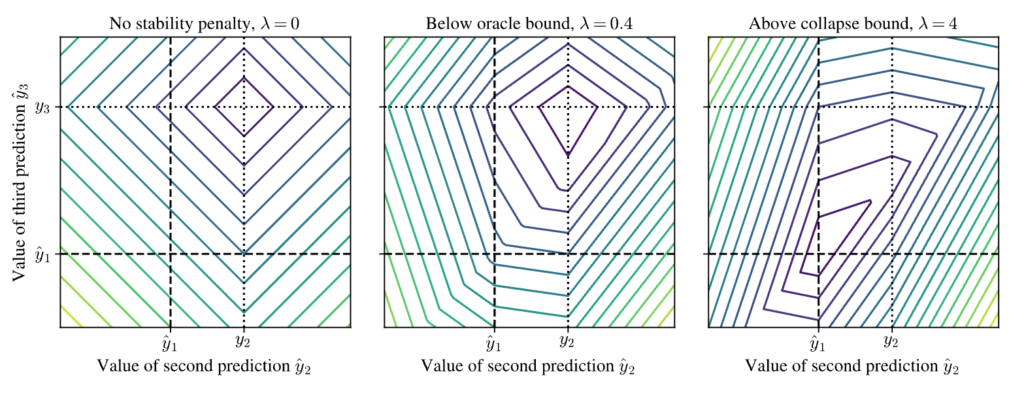
이걸 단순히 생각하면 그러면 \(\lambda\)가 작을때는 accuracy만 완벽히 맞으면 최소 loss니까 stabilization 학습이 안되는거 아니냐고 생각할 수 있는데, 실제로는 모델이 target을 완벽하게 예측하는것은 불가능하다. 그리고 실제로 완벽히 예측했으면 stabilization도 필요없는것이 맞다.(실제 비디오랑 완벽히 일치할것이기 때문에). 그렇다면 oracle bound를 제시하는게 무슨 의미가 있냐? 라고 할수가 있는데, 이 논문에서 얘기하는것은 \( \lambda\)가 일정 값 이하면, 모델이 target을 정확하게 예측하는데에는 영향을 끼치지 않으면서 stabilization 학습이 가능하다는 것이다. 쉽게 말해 정확도 손실 없이 stabilization이 가능한 \( \lambda\)의 범위가 존재한다는 의미이다.
위의 2d plot으로는 잘 설명이 안되는 부분이 있어서 이걸 한번 3d plot으로 만들어봤는데 아래와 같다.
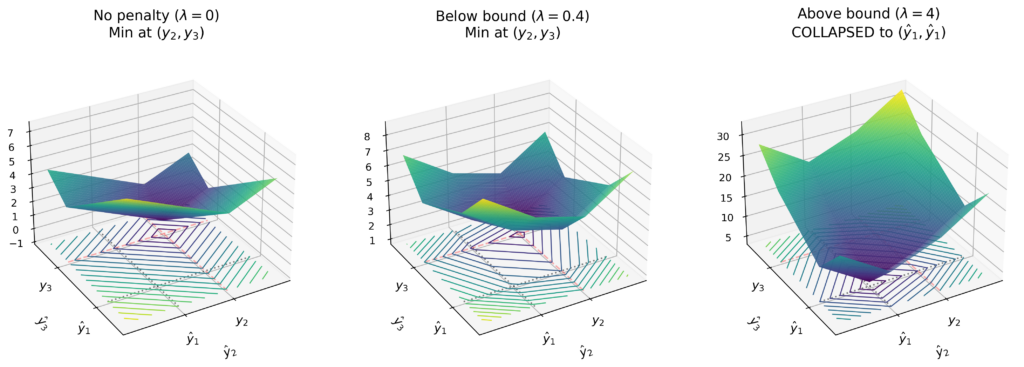
collapse는 넘어가고 \(\lambda\)가 0일때와 0.4일때 모두 accurate target일때가 가장 loss가 작기 때문에 optimization을 하면 정확하게 output을 맞출려고 하는데 실제론 정확하게 저 최소 loss에 도달할수는 없기 때문에 최솟값 근처에서 output이 나오게 될텐데 그 output이 stabilization loss가 들어가면서 \(\hat{y}_1\)에 가깝게 찍히고 output이 안정화된다는 이야기이다.
하지만 결국 이것은 theoritical한 이야기이고 다양한 이유가 있겠지만 실제로 이를 적용해보면 그냥 \(\lambda\)값에 따른 accuracy-stability trade-off가 그대로 존재한다.
Designing Stabilization Adapters
모델 design에 앞서 몇가지 원칙이 있다
- casual stabilizer : 이전 프레임만 볼수 있고 미래의 프레임은 사용하지 않는다. 스트리밍같은 real-time application에서 유용하게 쓰기 위함이다
- feature와 output 모두 stabilization을 한다 : 몇몇 low-level task에서는 output only stabilization도 가능한데 feature 도메인에서 stabilization을 적용하면 high-level task에서도 사용가능하게 만드는데 용이하다.
- 기존 모델 parameter와 independent하게 동작 : 기존 모델의 변형 없이 그대로 사용가능하게 만들고 modular형식이 되게하기 위함이다.
이런 원칙으로 시작해서 가장 간단한 방식으로 시작한 방식은 Exponential moving average(EMA) 방식이다. 아래와 같은 방식으로 현재의 stabilized되지 않은 output인 \(z_t\)와 이전의 stabilized된 output, \(\tilde{z}_{t-1}\)를 averaging하는것이다.
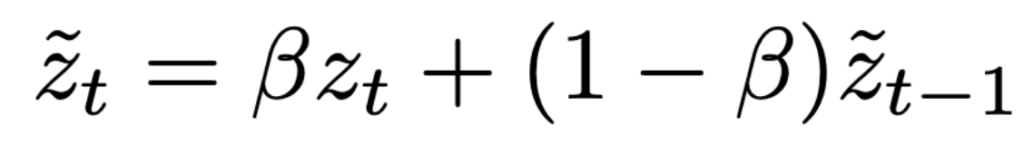
위의 식은 단순히 \(\beta\)를 정해서 모든 layer에 똑같이 적용되게 되는데 이를 각 layer에 적용하면 layerwise stablization이 된다. 또한 이를 더 flexible하게 구하기 위해 이전 input도 보고, featrue도 보게 해서 timestep과 상황에 따라 다르게 하기 위해 아래와 같은 구조로 stabilizer를 넣게 된다.
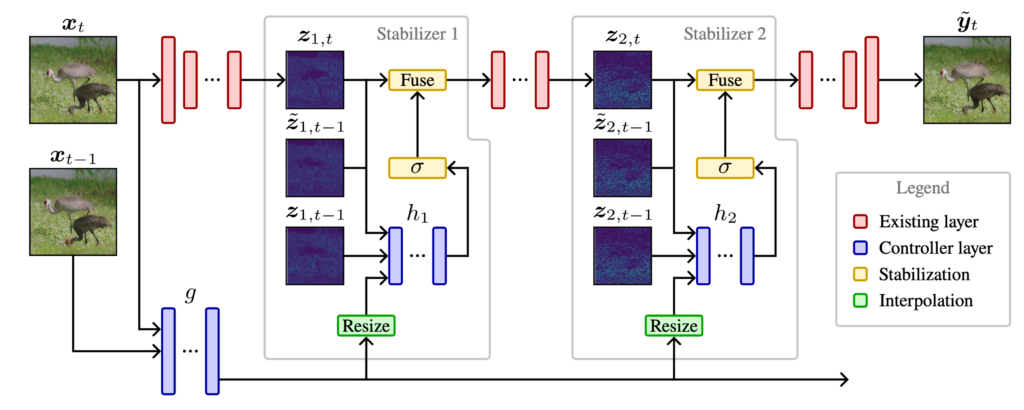
이전 input과 feature들을 받아서 얼마나 mixing해줄지 \(\beta\)를 구해주는 네트워크 \(g, h\)를 가볍게 달아서 사용하고 식으로 표현하면 아래와 같아진다.
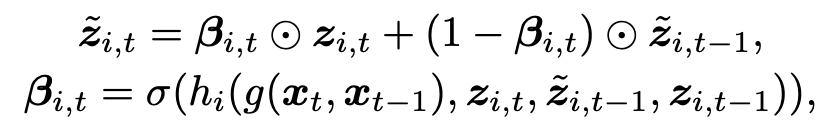
이제 \(\beta\)를 각 layer별로, 그리고 timestep별로 모두 구하게 돼어 layer \(i\),와 timestep \(t\)가 index로 생기게 된다. 또한 \(\beta\)를 단순 scalar값이 아니라 픽셀별로 모두 다르게 적용이 되게 만들면서 feature map사이즈와 같은 tensor의 형태로 만들어서 벡터로 표현되게 된다.
지금 \(z\)와 \(\beta\)는 모두 simple하게 보면 2d feature map으로 볼수 있고 이전 feature map과 현재 feature map을 단순히 elementwise로 mixing해주는 수준으로 볼수 있는데, timestep에서 움직이 존재하면 이 방법의 한계가 존재한다. 예를들어 object가 원래 t-1 에선 (1,1)위치에 있었는데 t에선 이동해서 (2,2)에 존재한다면, 이상적으로는 (2,2)픽셀의 값은 이전 t-1의 (1,1)픽셀과 averaing하는게 좋을것이다. 이를 가능하게 하기 위해 최종적으로 kernel을 사용하는 spatial fusion방식을 적용하게 된다. 예를들어 (2,2)위치에 pixel을 mxing할때 이전 프레임의 (2,2)만 가지고 하는것이 아니라 (1,1), (1,2), (1,3), (2,1), (2,2), (2,3), (3,1), (3,2), (3,3) 픽셀을 모두 가져와서 원래 object가 어디 위치에 있었는지를 파악해서 그 픽셀과 현재 픽셀을 섞을수 있으면 더 성능이 올라갈여지가 있다. 특히 비디오가 더 dynamic해져서 움직이는 동작이나 픽셀이 많으면, 이전 픽셀의 위치를 그대로 가져와서 mixing하는건 오히려 안좋을수도 있기 때문에 이러한 spatial fusion이 더욱 필수적이다. 식으로 표현하면 아래와 같아진다. (아래 식에서 윗줄의 오른쪽항에서 \(\tilde{z}_{t,c,k}\)라고 써있는건 표기 실수인것 같고 \(\tilde{z}_{t-1,c,k}\)이어야 되는것 같다.)
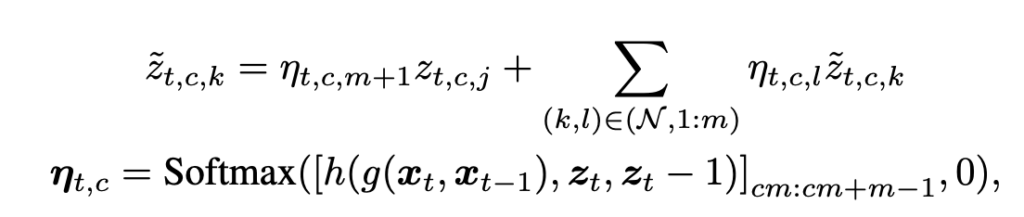
Experiments
실험에서 사용한 task는 먼저 크게 image enhancement / image denoising 가 있고, 다양한 corruption이 있는 상황에서 enhancement, denoising, depth-estimation도 실험했다.
실험 세팅을 먼저 설명하면
- Base model – image 기반 모델을 그대로 적용
- Output fixed – output을 ema를 이용해 avearaging하는데 고정된 \(\beta\)값을 이용
- Simple fixed – output과 feature를 고정된 \(\beta\)값으로 averaging
- Simple learned- \(\beta\)값을 layerwise로 학습을 시키는데 모델을 통해서 \(\beta\)값을 얻어내는게 아니라 그냥 layerwise로 \(\beta\)값을 하이퍼파라미터처럼 두고 튜닝하는식
여기까지는 \(\beta\)가 scalar 값으로 전체 feature를 통채로 averaging해주는것이고 아래는 pixel단위로 \(\beta\)값이 정해진다.
- Controlled – \(\beta\)값을 네트워크 \(g, h\)를 통해 얻어내는 방식
- Spatial – kernel까지 사용해서 주변픽셀을 보고 mixing해주는 방식
아래는 enhancement에서 실험한 결과이다.
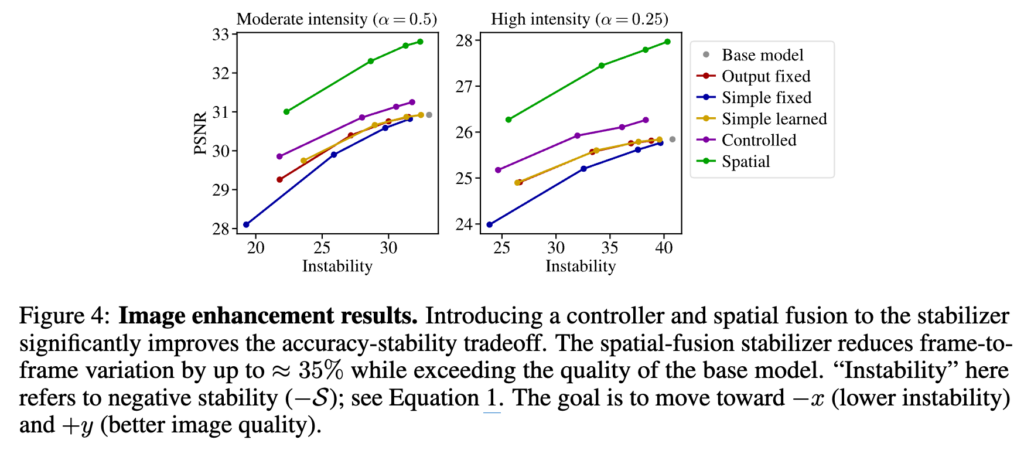
보면 controlled방법 이전까지는 단순 psnr과 stability의 trade-off처럼 보이고 controlled방법만 해도 psnr과 stability가 모두 좋아지는 영역으로 가고 Spatial 방법까지 쓰면 psnr과 stability가 매우 좋아지는 영역으로 간다. 원래 이미지만 보던 모델이 이전 프레임 정보도 같이 쓰게 되니까 당연한것 같으면서도 그러면 굳이 비디오 모델을 따로 만들필요 없이 간단한 stabilizer만으로도 비디오의 장점을 충분히 활용할 수 있는건가 싶기도 하다. 그리고 spatial fusion에서 성능이 확 좋아지는건 약간 task 특성이라고 하는데 enhancement는 아주 약간의 motion만 있어도 픽셀값이 많이 달라져서 그런것 같다.
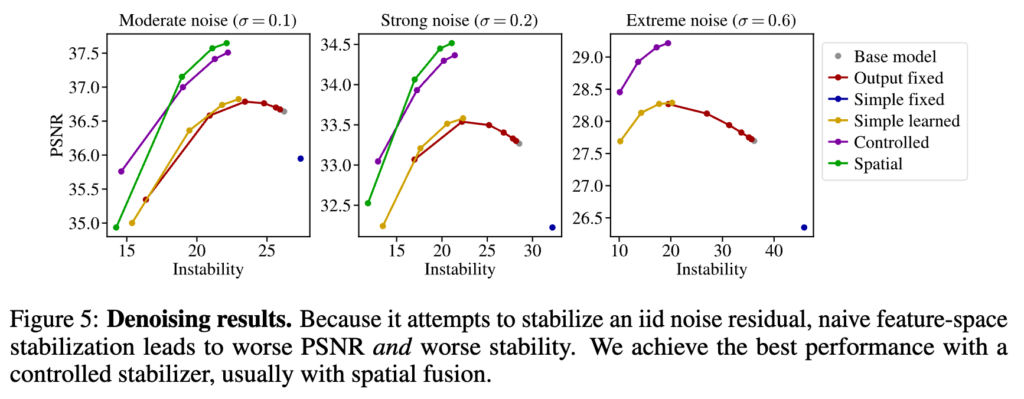
아래는 denoising결과이다. 여기서도 비슷한데, 먼저 enhancement task에 비해 spatial fusion의 효과가 약간 덜하다. 그리고 simple fixed 방법이 base model보다 psnr도 안좋고 stability도 안좋아지는점이 특이점인데, denoising 특성상 feature map이 이미지를 예측하는게 아니라 noise residual을 예측하도록 되어있는데 이게 이를 feature map에서 correlation이 없는거라 이걸 smooth하게 만들면 노이즈제거를 오히려 덜 하게 만들어서 역효과가 난다.
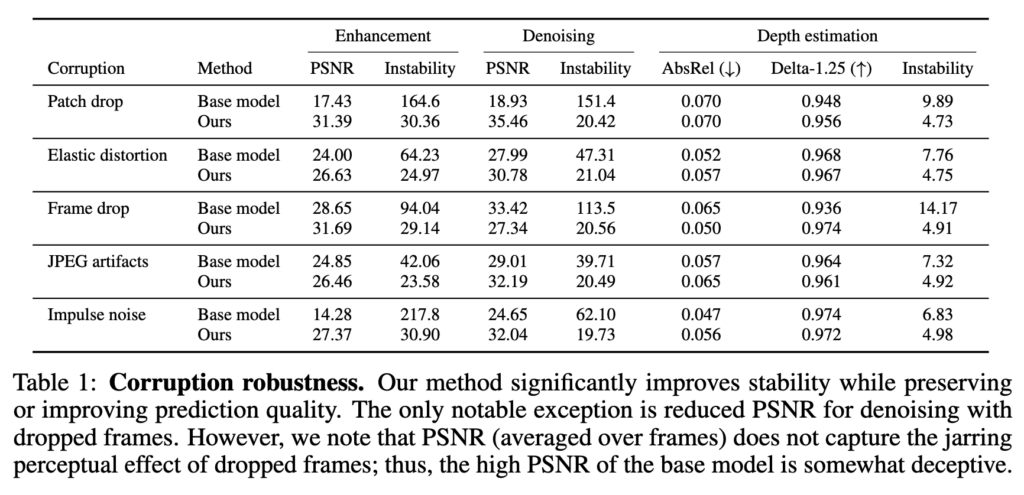
다음으론 corruption robustness에 대한 실험인데, 이미지 모델을 사용하돼, input에 학습 되지 않은 corruption인 patch drop, elastic distortion같은 corruption이 들어오는 상황에 stabilizer 학습만으로 얼마나 회복이 되는지에 대한 실험이다. 맨 위에 sample video에 이 상황에 대한 qualitative 결과가 다 들어가있다. 사실 좀 당연한 결과인데 corruption을 전혀 배우지 않은 이미지기반 모델은 이런 corruption이 들어오면 거의 아무것도 하지 못해서 성능이 매우 떨어진다. 여기서 stabilizer가 학습되면서 이전 이런 corruption들을 이전 feature를 활용해서 cover할수 있게 학습을 하니까 성능이 회복되는것은 거의 당연해 보인다. 그래도 그 수치자체가 매우 높고 qualitative결과에서도 꽤나 훌륭한 결과를 보이는것이 corruption에 대한 대비를 하기 위해 이미지 모델 전체를 재학습할 필요는 없다는 것을 보여주는게 의미가 있는것 같다.
마지막으로 adversarial 한 weather (비, 눈)에서도 실험을 하는데 여기선 basemodel까지 학습을 했을때 어떻게 되는지 보여준다.
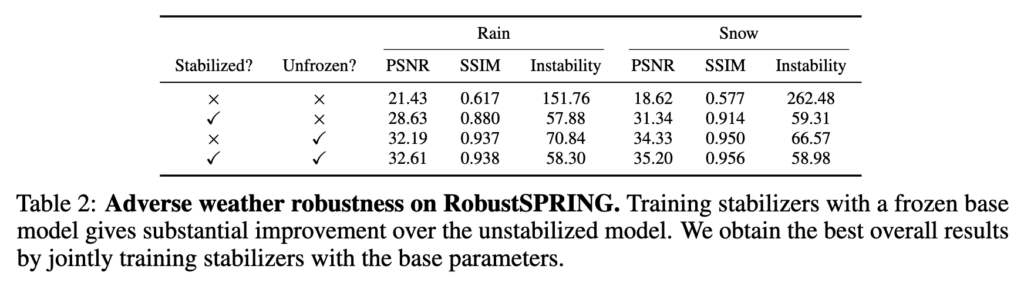
비나 눈같은 경우에도 이전 프레임에서 정보를 가져오면 쉽게 회복이 가능한 부분이 많아서 stabilizer만으로도 성능이 꽤나 올라가는데, base모델을 학습하면 훨씬 psnr이 좋아진다. 한가지 주의점은 base model만 학습을 하면 psnr은 좋아지는데 stability는 오히려 stabilizer만 학습한것보다도 안좋다. 반면 둘다 학습을 시키면 훨씬 좋아진다.
Conclusion
이미지 모델을 그대로 활용하돼 stabilizer만 학습시켜서 비디오에서 적용한다는 아이디어 자체가 되게 practical하고 좋다는 생각을 했다.
한계점이라면 각 상황에 따라 모두 stabilizer를 각각 학습시켜야된다는것, 이미지 모델마다 또 각각 stabilizer를 학습시켜야된다는것, 그리고 stability에 적용하는 loss가 너무 naive하다는것, 등등 꽤나 많고 증명을 생략했지만 theoritical한 anlysis도 가정이 몇가지 있는데 실제로 잘 맞는 가정은 아니다. 그래서 논문의 기본 아이디어를 기반으로 발전시켜서 해볼 연구가 많다는 느낌을 받아 후속 연구를 다양하게 해보려고 한다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.