Introduction
2022 CVPR에 나온 ‘All-In-One Image Restoration for Unknown Corruption (AirNet)’ 을 시작으로 All-in-one restoration에 대한 논문이 많이 나오고 있는 것 같다.
All-in-one image restoration의 기본적인 컨셉은 수많은 restoration task들 (Denoising, Deblurring, Deraining, Desnowing, Dehazing 등등) 을 각각 따로 학습시키지 않고 네트워크 하나로 학습을 하겠다는 것이다. 모든 task를 각각 따로 학습시키는 것이 너무 번거롭고 각각 학습시킨 네트워크를 별개로 저장해놔야 하기 때문에 메모리관점에서도 비효율적이기 때문이다.
이 논문에서 all-in-one resotration을 위한 기본적인 컨셉은 prompt를 이용하는 것이다. network의 block들 사이에서 feature를 이용하여 prompt를 만들고 prompt와 feature를 다시 섞어서 새로운 feature를 만든다. 이 때 feature는 degradation에 대한 정보를 갖고 있기 때문에 prompt또한 degradation정보를 갖게 되고 prompt와 feature를 다시 섞을 때 prompt가 degradation 종류에 따른 guide를 해주는 느낌이다.
Method
기본적으로 Archiecture는 Restormer(Restormer: Efficient Transformer for High-Resolution Image Restoration(2022 cvpr))를 거의 그대로 따르고 있다. 아래의 overview figure를 보면 restormer와 굉장히 흡사하게 그려놨다.
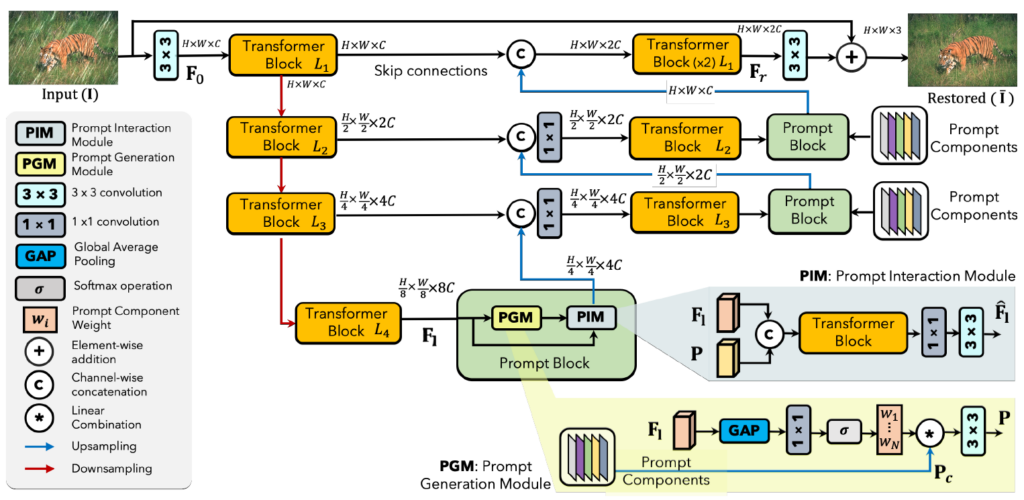
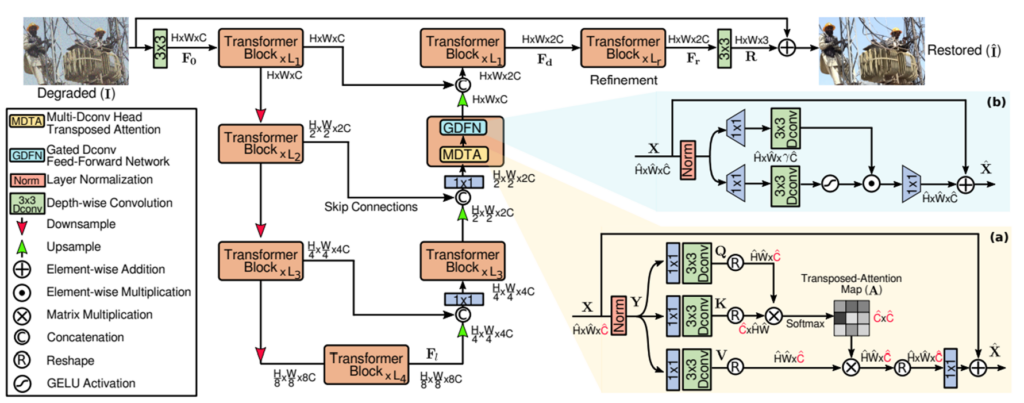
기본적으로 Restormer 구조에 Decoder쪽에 Prompt Block을 하나씩 붙여서 만든 구조이다.
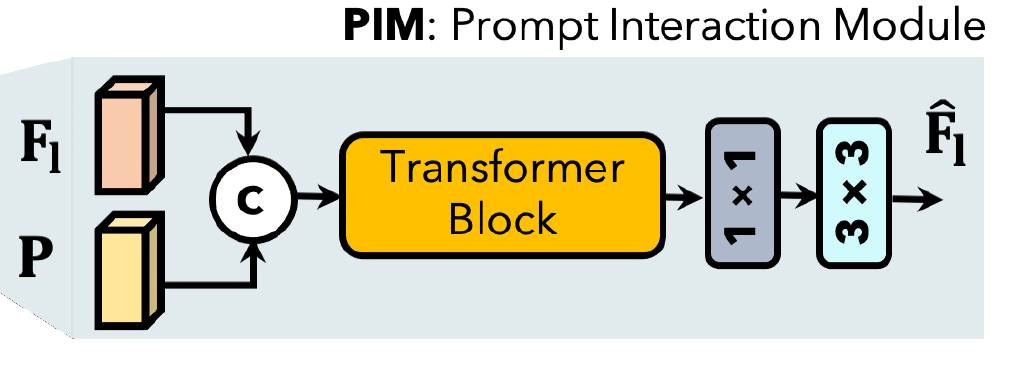
Prompt Block은 Prompt를 만드는 PGM(Prompt Generation Module)과 생성된 prompt와 feature를 합치는 PIM(Prompt Interaction Module) 으로 이루어져 있다.
PGM : Prompt Generation Module

먼저 PGM은 Prompt Components(\(P_c\))와 네트워크 중간 feature(\(F_l\))를 받아 Prompt(\(P\))를 생성한다.
Prompt Component는 learnable parameter로 되어 있고 가장 깊은 layer의 size와 같게 되어있으며 N개가 존재한다. 즉, dimension은 아래와 같다.
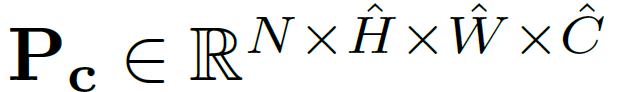
이 Prompt와 feature가 결합하는데 먼저 feature에 global average pooling, 1×1 convolution, softmax를 적용한다. 즉 feature를 일종의 weight로 변환시키고 Prompt Component에 곱해줘서 새로운 Prompt를 만들고 N개의 Prompt를 모두 더해준 뒤 최종적으로 3×3 convolution에 태워 최종 Prompt를 output으로 내보낸다. 식으로 표현하면 아래와 같다.
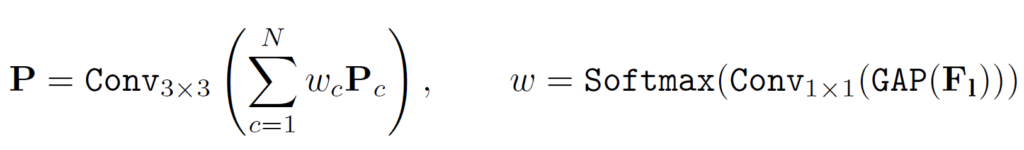
(decoder level이 올라가면서 feature 사이즈가 커지는데 이를 맞춰주기 위해 prompt component에 bilinear upsampling을 적용해 사이즈를 키워준다고 한다.)
PIM : Prompt Interaction Module
사실 굉장히 간단하고 PGM에서 생성되어 받은 Prompt(\(P\))와 feature를 concatenation 한 뒤 Transformer block에 넣고 1×1, 3×3 convolution에 태워주면 끝이다.
Experiment
all-in-one setting
먼저 제일 중요한 all-in-one setting에서의 성능이다. 이전 work인 Airnet의 세팅을 똑같이 따라서 Dehazing, Deraining, Denoising에 대해 학습시키고 결과를 비교했다. 이전 all-in-one sota network인 Airnet보다도 성능이 꽤 좋다. 하지만 이게 과연 fair한 비교인지는 잘 모르겠다.
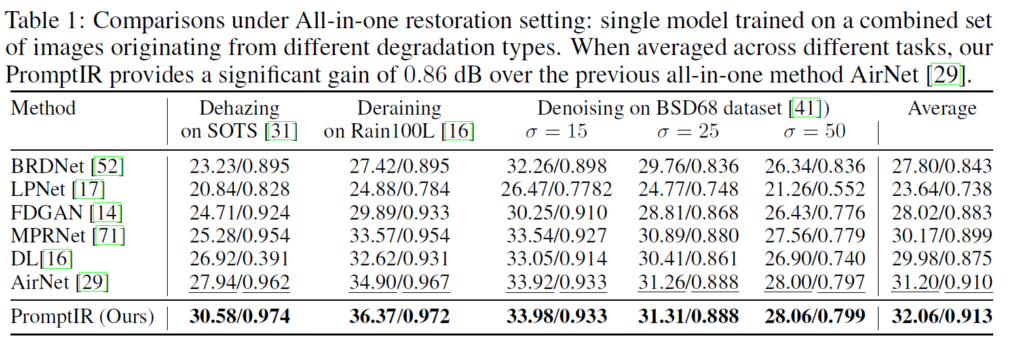
fiar한 비교를 위해 아래 table을 보면 기본 baseline인 Restormer와 all-in-one 성능을 비교한 것인데, 이미 그냥 restormer가 airnet보다도 성능이 좋다.

그리고 promptIR 방법을 적용했을 때 성능이 오르긴 하는데 일단 restormer에 이것저것 붙인것이 꽤 많고 심지어 Prompt Block안에 Restormer 기본 구조인 Transformer Block도 들어있어서 연산량 자체가 꽤 늘어났을 것 같은데 이게 과연 prompt ir method가 효과가 있다고 하는 것이 옳은것인지 Restormer 네트워크에도 비슷한 만큼 연산량 수를 늘려서 비슷한 연산량으로 비교를 해봐야 fair할 것 같은데 그런 비교 결과는 없다.
task specific setting
ablation 실험이 굉장히 많은데 먼저 all-in-one학습이 아닌 task-specific하게 학습했을 때의 결과도 모두 report 해놨다.


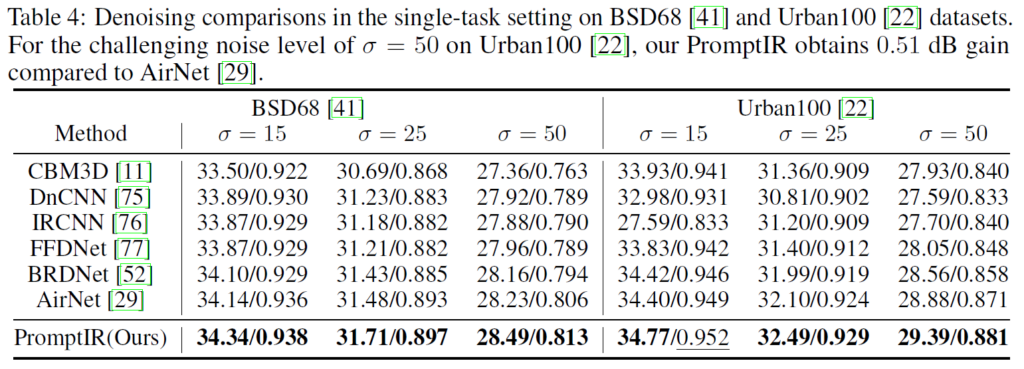
task-specific하게 했을 때 모두 restormer, airnet 등등 baseline보다 성능이 높다. 하지만, restormer 구조에 이것저것 추가한 PromptIR이 당연히 성능이 더 좋아야 하는 것 아닌가? 라는 생각도 들었다.
Learnable Prompt
또한 learnable prompt의 장점도 확인하기 위해 prompt를 fixed한것과의 결과도 report 되어 있다.
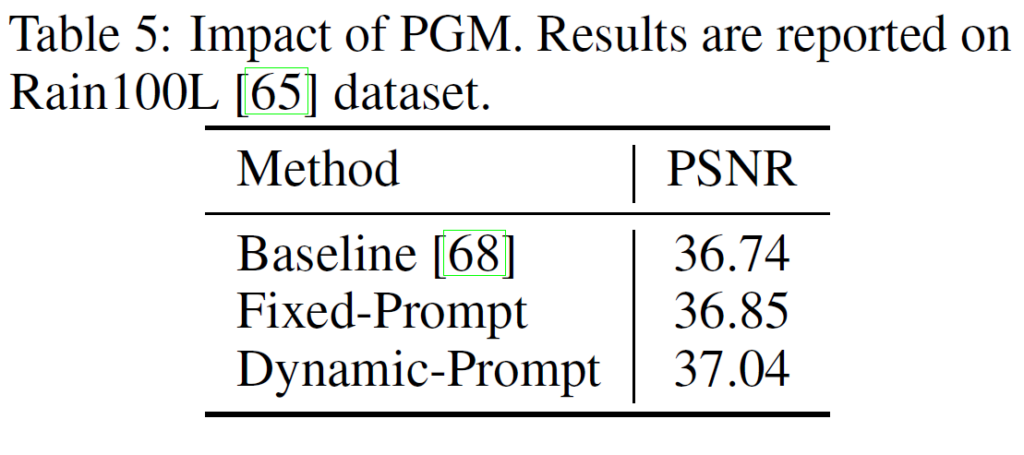
Deraining 세팅에서 그냥 restormer보다 fixed prompt를 사용하면 성능이 조금 오르고 learnable prompt를 사용하면 조금 더 성능이 오른다는 table이다.
그런데 이 prompt의 목적이 사실 all-in-one setting에서 degradation 종류를 파악해주고 guide 해주는 역할인데 왜 결과 비교는 task-specific하게 deraining 에서만 해서 비교했는지가 굉장히 의문이다. 즉, prompt가 과연 all-in-one setting에서의 학습을 도와준 것인지 아니면 단순히 network의 resotoration 성능을 올려준 것 인지가 오히려 모호해지는것 같다.
Combination of Degradation datasets
이 외에 조금 흥미로운 결과는 denoising, deraining, dehazing dataset을 각각 다른 조합으로 학습시켰을 때의 결과이다.
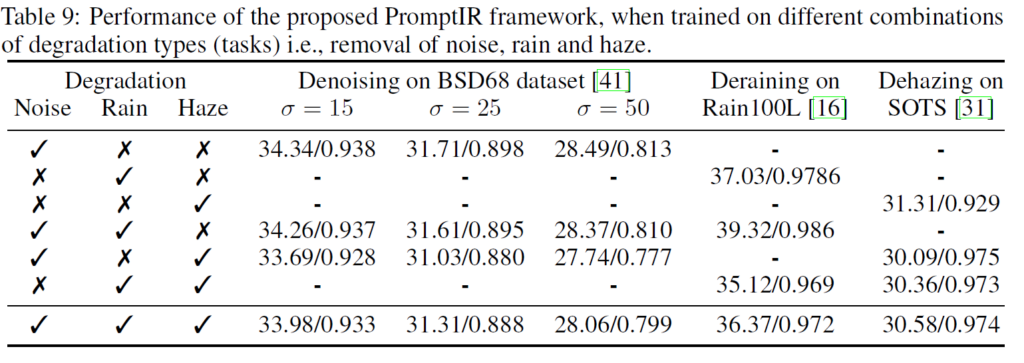
기본적으로 여러 dataset이 섞이면 전체적으로 성능이 떨어질 것 같은데 deraining 같은 경우에는 denoising 데이터셋과 같이 학습시키면 꽤 유의미하게 성능이 오른다. 반면 denoising에서의 성능은 거의 변동이 없다. 또한 Dehazing 데이터셋은 다른 데이터셋과 섞이면 성능이 꽤 떨어진다.
이러한 현상이 Airnet paper에서도 비슷하게 나타났었다. 아래는 Airnet 에서 같은 세팅으로 실험한 결과이다.
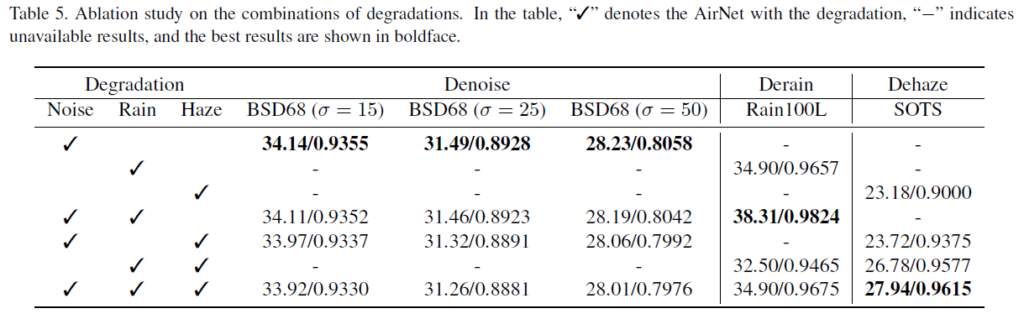
Airnet에서도 Denoising과 Deraining 데이터셋을 같이 학습시키면 Deraining 성능이 꽤 올랐고 Dehazing 같은 경우에도 다른 데이터셋과 같이 학습시키면 성능이 꽤 올랐다.
Airnet 논문에서도 이러한 현상에 대해 정확한 원인을 모르겠다하고 넘어갔었는데 이 paper에서도 원인에 대한 얘기는 없고 현상에 대한 얘기만 있다. 원인을 제대로 알 수 있으면 응용해서 의미있는 all-in-one 학습을 할 수 있지 않을까하는 생각도 든다.
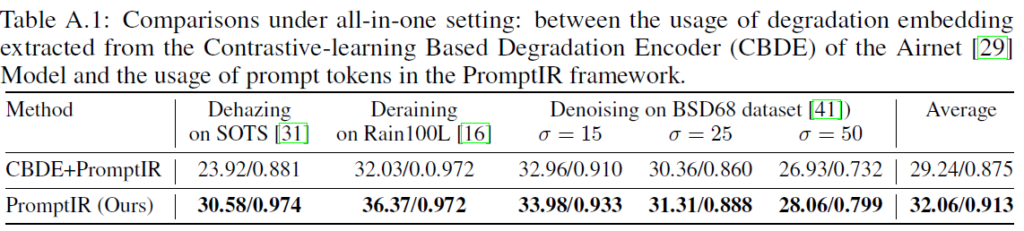
Comparison with contrastive learning
PGM으로 Prompt를 생성하는 대신 Airnet에서 사용된 CBDE(Contrastive-learning Based Degradation Encoder) block을 사용해 embedding을 뽑고 contrastive learning으로 학습시켜서 결과를 비교해보았다는 내용이다.
Conclusion
사실 정말 all-in-one 학습을 위한 novel한 method도 딱히 없는 것 같고 단순하게 ‘learnable prompt를 섞어 네트워크 성능을 올렸다’ 정도가 끝인 것 같다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.