이전 포스팅에서는 가치 함수(Utility function or Value function) 이나 Q-fucntion을 이용하여 학습하는 방법에 대해 설명했고 이번 포스팅은 Policy를 이용하여 학습하는 방법을 설명한다.
Policy Search
Policy(\(\pi\))란 주어진 state에서 action을 매핑해주는 함수라고 했고 이러한 Policy를 파라미터화(\(\pi_\theta\)) 하여 최적의 Policy를 찾아내는 것이 Policy search의 목표가 된다.
이를 위한 간단한 예시로 policy를 아래와 같이 represent할 수도 있다.
\( \pi(s) = argmax_a Q_\theta(s,a) \).
위에서 Q 함수는 linear 함수일 수도 있고 deep neural network로 이루어진 non-linear 함수일 수도 있다. 위와 같은 식으로 policy를 찾다보면 Q함수를 찾는 Q-learning과 비슷하게 보일 수도 있으나 실제 Q값을 근사하기 위한 Q-learning과 달리 policy search 방식은 실제 Q값과 비슷하게 Q-function을 찾는 것이 아니라 최적의 결과를 내는 Q-funciton을 찾는 것이 목표라는 것이 다르다. 이 과정에서 Q-funciton이 실제 Q값과 유사해질 수 있지만 그것 자체가 목표인 Q-learning과는 다르다는 것이다.
위와 같은 식으로 문제를 풀 때 action에 따라 policy가 불연속적인 함수가 되어 미분이 불가능해져서 gradient-based 방법을 쓰기 어려워질 때가 있는데 이럴 때 stochastic policy 방법을 이용해 특정 state 에서 action을 확률적으로 선택하게 하여 미분 가능하게 만들어 해결하기도 한다.
Applications
Deep Q-networks (DQN) : 2012년 구글 Deep-Mind에서 개발한 시스템으로 첫 modern deep RL system이라고 한다.
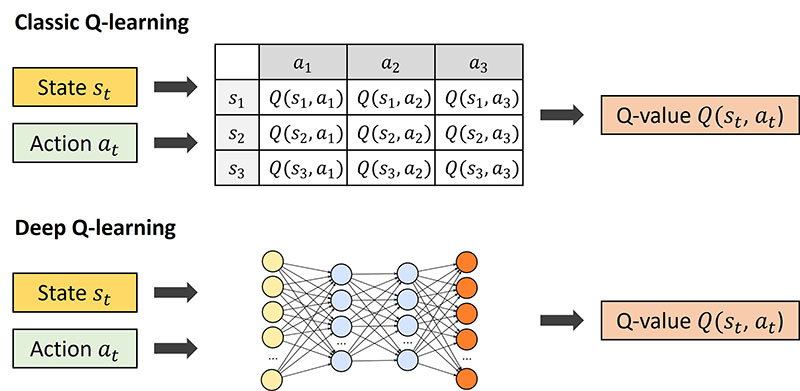
기존에는 Q함수를 추정하고 학습하기 위해 위의 그림과 같이 table형태로 저장하거나 하는 방식을 이용했다. 하지만 어떤 시나리오에서는 state와 action의 수가 셀 수 없이 많아지는 경우도 있고 위와 같은 table로 추정하기 어려운 경우가 많이 발생하는데 Deep learning방식을 이용하면서 손쉽게 non-linear 함수로 만들수 있고 gradient를 이용해 최적화 시킬 수 있게 된 것이다.
이외에도 policy 함수를 deep neural network로 대체할 수도 있고 강화학습에 사용되는 함수들을 deep neural network를 사용해 근사하여 문제를 해결하는 방식이 많다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.