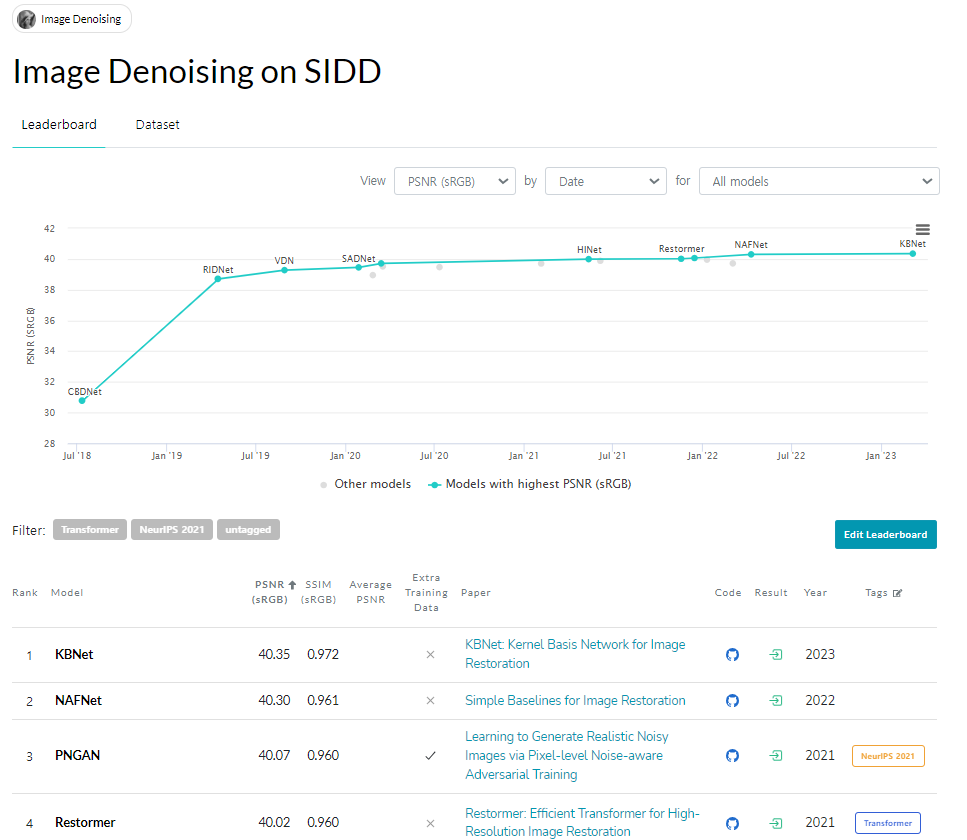
2023.12.26 기준, KBNet에 살짝 밀렸지만 아직도 Image denoising 분야에서 거의 SOTA 성능을 찍고 있는 NAFNet을 제시한 논문인 Simple Baselines for Image Restoration 논문에 대해 리뷰 하고자 한다. (ECCV 2022)


1. Introduction
Deep Learning을 이용한 image restoration분야(denoising, deblurring, super-resolution 등등)는 놀라운 성능을 많이 보여주었다. 이 논문에서는 기존 방법들의 간단한 변형으로 system complexity를 낮추고 SOTA 성능을 찍을 수 있었다는 것을 보여준다.
먼저 이 논문에서는 기존의 방법들의 complexity를 두 가지로 나눠서 분석한다.
(1) inter-block complexity
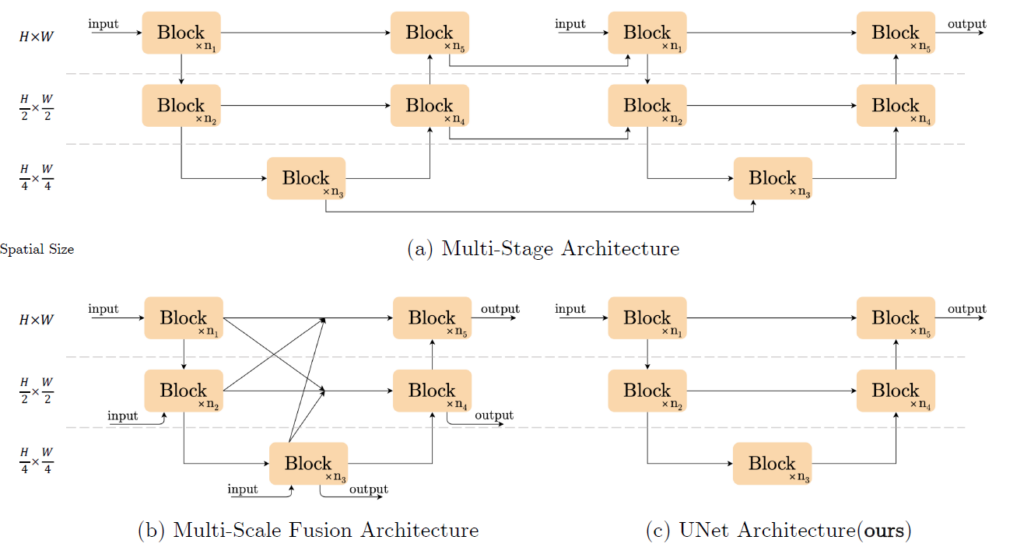
위의 그림의 (a)와 (b)같이 multi stage방식 또는 다양한 level의 feature 를 fusion해서 사용하는 방식 등이 complexity를 높였다고 얘기하면서 바꿔 simple한 U-Net 방식인 (c)의 방식으로 사용했다고 한다. 원래는 더 높은 성능을 위해서 (c)방식을 변형해 (a)와 (b)같은 방식을 사용한 것이지만 이 논문에서는 (c)의 방식으로도 SOTA성능을 얻을 수 있었다고 말한다.
(2) intra-block complexity
inter-block complexity를 block끼리 연산을 어떻게 상호작용 시킬 지를 보았다면 intra-block complexity는 block을 어떻게 구성할 것 인지를 본다.
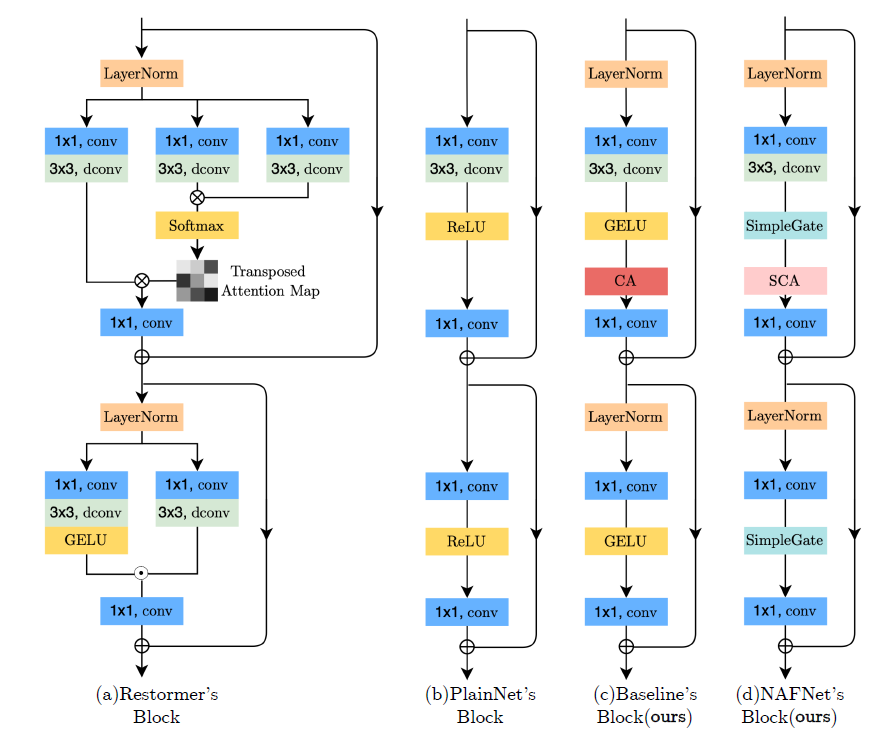
위 그림의 (a) 처럼 복잡하게 block을 구성할 수 도 있지만 마찬가지로 complexity를 증가 시킨다고 말하며 (b)방식으로 간단하게 만들어 시작한 후, SOTA 방법들을 이용하여 몇 가지 연산을 추가하고 변형해 complexity를 낮춘 baseline인 (c) 방식을 만들고, 한번 더 변형시켜 (d) 방식으로 만들어 사용하여 간단하면서도 높은 성능을 얻을 수 있었다고 말한다. Baseline에서 이미 다른 method보다 연산량, 성능에서 모두 SOTA를 달성하였으나, (c) 방식에서 사용된 GELU와 CA(channel Attention Module)의 의미를 재해석 해서 변형해 (d) 처럼 nonlinear activation이 없는 네트워크를 만들어 더 성능을 높였으며 Nonlinear Activation Free 네트워크 즉, NAFNet 이라고 이름지었다.
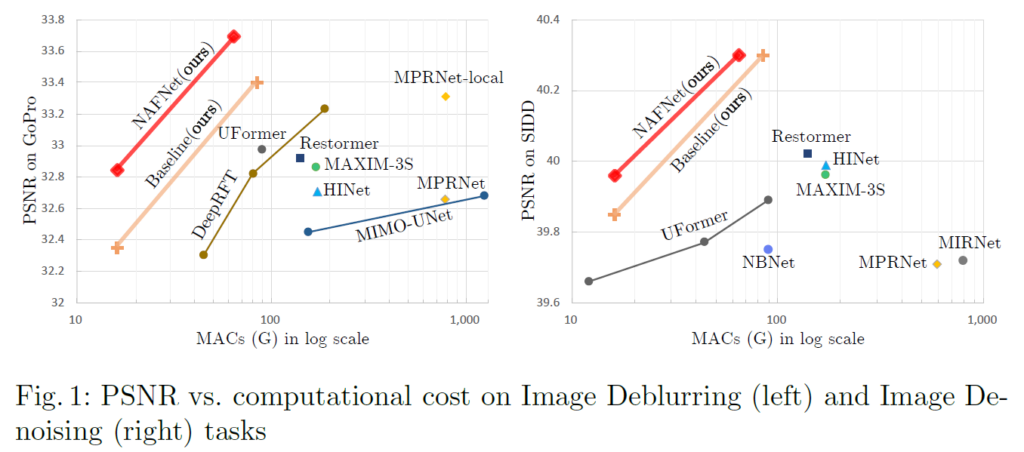
2. Related work
(1) GELU (Gaussian Error Linear Unit) : GAUSSIAN ERROR LINEAR UNITS (GELUS) 논문 참고
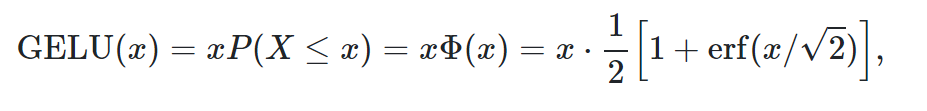
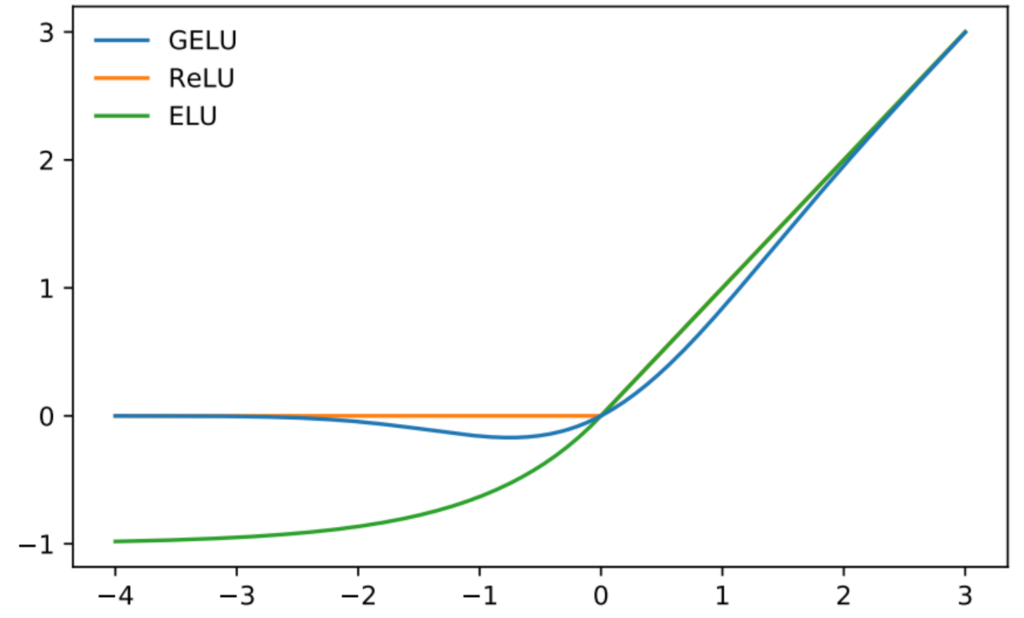
거의 모든 model에서 GELU가 RELU보다 좋은 성능을 보였다고 말한다.
(2) GLU ( Gated Linear Unit )
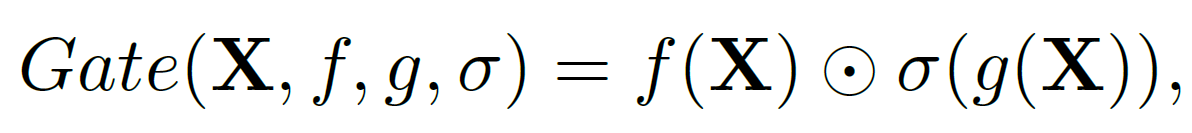
원래 GLU 연산 : input을 각각 linear transformation에 태우고 하나는 nonlinear activation에 태우고 나머지는 그대로 가져와서 element-wise product 진행한다.
NLP에서 굉장히 효과적으로 작동하는 것으로 나타났고 computer vision에서도 유용하게 사용되는 중이다. 이 논문에서는 이 GLU에서 nonlinear activation을 제거해 nonlinear activation free GLU를 제시한다. 두 개의 linear transofrmation의 곱이 nonlinearity를 만들기 때문에 GLU 자체가 nonlinear한 성질을 가지고 있음을 말하며 nonlinear activation을 제거해도 performance degradation이 없었으며 최초로 nonlinear activation function없이 모델을 만들었다고 주장한다.
3. Method for Baseline
3.1 Architecture
simple한 Unet 구조 그대로 사용하면서 architecture가 성능의 barrier가 아니라고 주장한다.
3.2 Plain Block
제안한 model인 Baseline과 NAFNet을 만들기 전에 Plain block을 구성하고 시작되는데, Plain Block은 convolution, Relu, shortcut등등 흔하게 사용되는 방법들로 구성되어있다. Transformer를 사용하지 않은 이유는 1. SOTA에 transformer가 필수적이지는 않은 것 같다, 2. depthwise convolution이 self-attention 메카니즘보다 간단하다, 3. 이 논문은 transformer의 장단점을 얘기하려는 논문이 아니며 simple한 baseline을 제공하려는 목적이기 때문이다. 라고 한다.
3.3 Normalization
Batch Normalization, Instance Normalization 등등 방법이 있으나 Layer Normalization 방법이 SOTA에 더 많이 사용된다고 얘기한다.
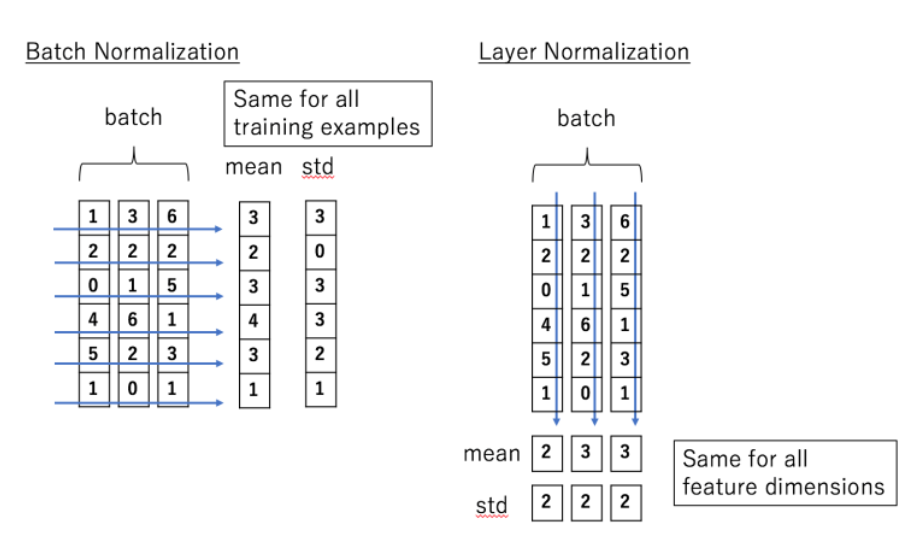
Plain block에서 시작해서 Layer Normalization을 추가해서 10배 더 큰 learning rate으로도 학습이 smooth하게 진행할 수 있었다고 한다. 더 큰 learning rate로 performance gain이 있었다고 얘기한다. 즉, Layer Noramlization으로 학습이 더 안정화 된다는 것이다.
3.4 Activation
GELU 사용한다. SIDD에서 비슷한 성능을 보이지만, GoPro에서는 performance gain이 있었다고 얘기한다. 즉, RELU 대신 GELU를 사용해 image denoising에서는 기존과 비슷, image deblurring에서는 기존보다 non-trivial gain을 얻을 수 있었다고 한다.
3.5 Attention
모든 feature의 attention을 계산해야하는 self-attention은 연산량이 많다. image resotration task는 high resolution을 다루기도 하는데 그 때 computation이 너무 높아져서 practical 하지 않다고 한다. 몇몇 연구에서는 self-attention을 fix-sized의 local window에만 적용하기도 했지만 global information이 부족하다는 한계점이 있다. 이 논문에서는 이러한 window-based attention을 사용하지 않아도 depthwise convolutiond으로 local 정보는 잘 얻을 수 있다고 얘기한다.
대신 channel attention을 사용하는데 computation efficiency와 global information 둘 다 얻을 수 있다고 얘기한다. 다른 논문들에서도 image restoration 분야에서 channel attention이 효과적이라고 검증되었다고 한다. 따라서 Plain block에 channel attention을 추가해서 SIDD와 GoPro dataset에서 둘다 성능 gain을 얻었다고 한다.
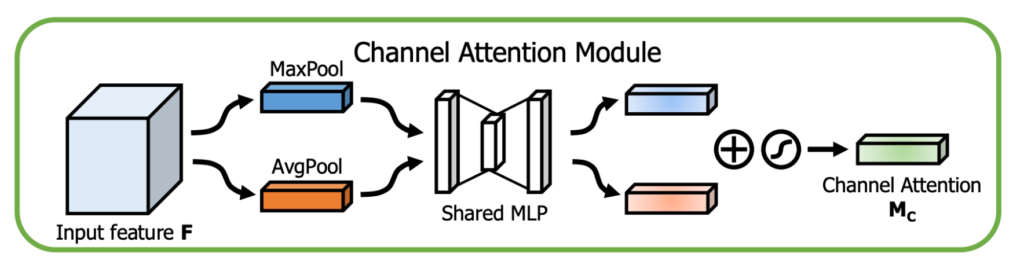
3.6 요약
많이 쓰이는 convolution, relu, skip connection등을 이용하여 plain block을 만들었고 거기에 gelu로 변형, layer nomalization, channel attention을 추가하여 Baseline을 만들었다. 간단하게 만들었음에도 불구하고 SOTA 성능을 보였다고 한다.
4. Method for Nonlinear Activation Free Network(NAFNet)
4.1 GLU
Baseline을 더 발전시키고자 SOTA 방법들을 찾아보다가 GLU와 GELU가 눈에 띄었다고 한다.
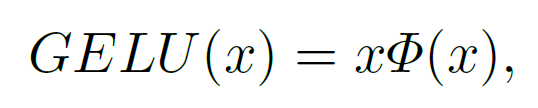
GLU와 GELU를 살펴보면 GELU는 GLU의 special case라고 얘기한다. f와 g가 각각 identity function이고 GLU의 σ를 Gelu의 ϕ로 바꾸면 같은 식이라는 얘기이다. 즉 activation으로 쓰인 GELU가 GLU의 연산 안에 있는 연산이고 따라서 GLU 자체로 nonlinearity를 포함하고 있다고 봐도 된다고 한다. 또한 GLU의 시그마를 제거해도 nonlinearity가 보장된다고 얘기하며 이를 이용해 간단한 SimpleGate(SG) 연산방식을 제안한다.
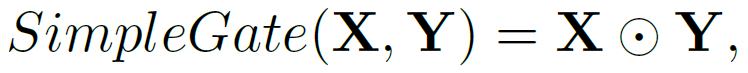
GELU를 위의 SimpleGate로 변환해서 사용하니 image denoising과 deblurring모두에서 더 성능이 좋아졌다고 한다.
4.2 Simplified Channel Attention
아직 channel attention에 사용된 sigmoid와 ReLU에서 nonlinear activation이 남아있다.
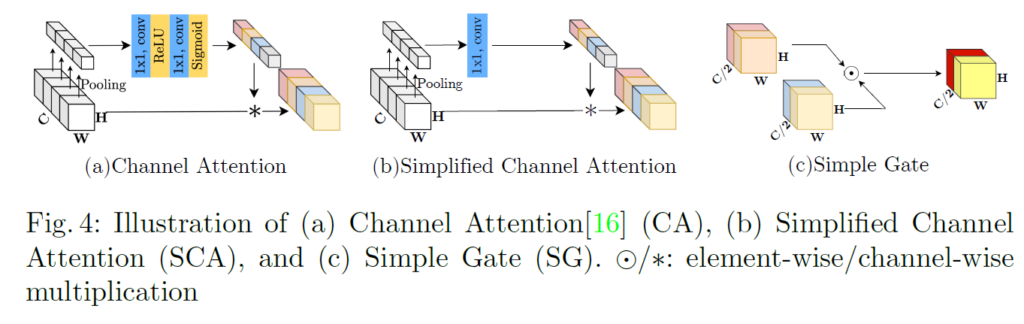
위의 그림의 (a)에서 보다시피 일반적인 channel attention에 ReLU와 sigmoid가 들어있다. 식으로 표현하면 아래와 같다.
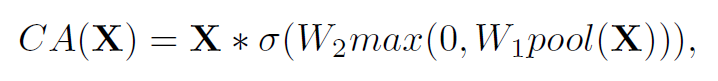
위 식에서 channel attention을 하는 과정을 간단하게 하나의 식이라고 생각하고 표현하면 아래와 같다.
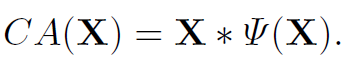
이 식은 또 위에서 GLU에서 사용된 식과 굉장히 유사해진다. 따라서 channel attention도 GLU의 special case로 취급해버리고 간단화 할 수 있다고 얘기한다. channel attention에 가장 중요한 global 정보와 channel 정보를 활용하는 부분만 남기고 간단화 하면 아래와 같은 식이 된다.
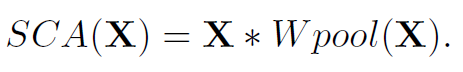
위의 식을 이용하여 더 간단하면서도 성능 손실이 없었고 오히려 denoising, deblurring에서 둘 다 약간의 성능 향상을 관찰했다고 한다.
4.3 요약
GELU를 SimpleGate로 대체, Channel Attention을 Simplified Channel Attention으로 대체하여 성능 향상을 관찰했다고 얘기함. 대체하면서 nonlinear activation이 완전히 없어져 Nonlinear Activation Free Network가 되었다(NAFNet).
5. Experiments

Layer Normalization을 사용하면서 learning rate을 높여 안정적인 학습이 가능했음. Layer Normalization, GELU, Channel Attention등등 방법을 하나씩 적용해가면서 성능이 향상되는 것을 보여준다.
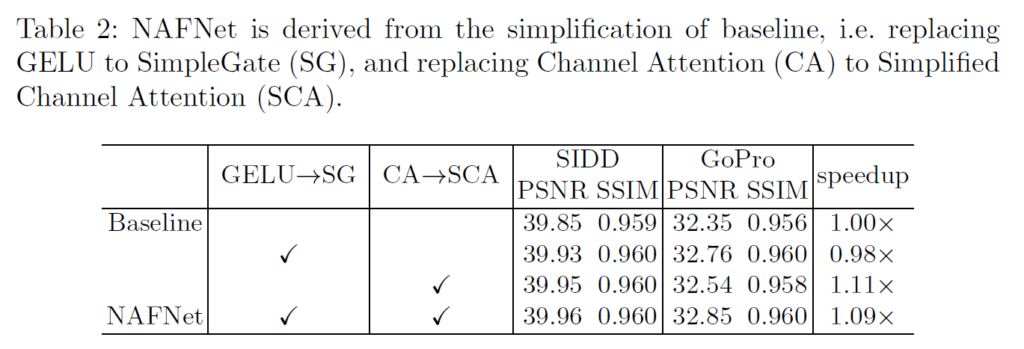
Baseline에서 GELU를 Simple Gate로 바꾸고 Channel Attention을 간단화 해서 사용했을 때 하나씩 적용해가면서 성능이 향상하는 것을 보여준다.
6. Conclusion
기존 SOTA method들을 잘 활용해 간단하면서도 더 좋은 성능의 network를 만들 수 있었다는 것이 결론이다.
추가
최근 NAFNet 관련 여러 실험을 해본 결과 다른 real noise dataset (ex. DND, Poly U, CC) 등에서 성능이 잘 안나오는 것을 확인할 수 있었다. SIDD로 training을 하면 딱 SIDD에서만 성능이 잘 나오고 SIDD 데이터셋에 존재하는 noise에 대해서 overfitting이 심하게 존재하는 것으로 보이며 이에 대한 해결방안이 필요할 것으로 보인다.
답글 남기기
댓글을 달기 위해서는 로그인해야합니다.