Stanford CS236 Deep Generative Models 수업의 자료를 기반으로 생성모델의 기본 개념들을 정리해보고자 한다. (참고 https://deepgenerativemodels.github.io/syllabus.html)
이전에 포스팅한 Autoregressive Models 에서는 모델을 어떻게 설계할까에 대해 주로 이야기했고 이제 이 모델을 어떻게 학습시킬까에 대해 이야기한다.

우리가 가지고 있는건 n개의 데이터 뿐이다. (x1, x2, …, xn). 이 데이터들이 어떤 확률분포 \( ( P_\text{data} ) \)에서 sampling된 것일지를 추정하는것이 목적이다. 이를 위해 x1, x2, … xn의 데이터들이 independent하고 identically distributed (IID) 하다고 가정한다. 이 데이터들을 가지고 확률분포를 예측할건데 이를 위한 모델들로 베이지안 네트워크나 이전 autoregressive 포스팅에서 썼던 FVSBN등등 다양한 모델을 사용할 수 있다.
어떤 두 분포간의 차이를 측정하고 비교하고자 할때 가장 먼저 나오는 개념이 KL-divergence 이다.

p와 q분포가 있을 때 샘플들인 x를 가지고 KL divergence를 측정하면 두 분포가 비슷할수록 KL divergence는 작아진다. p와 q가 동일하다면 log값이 항상 0이므로 KL-divergence값은 0이 되고 다른 경우에는 항상 0보다 큰 값을 가진다다. 따라서 KL-divergence를 최소화하는 것이 두 분포를 비슷하게 하는 목표가 된다. 우리는 그러므로 \( D(P_\text{data} || P_\theta) \) 를 계산해서 최소화하면 된다.
\( D(P_\text{data} || P_\theta) \)를 단순화하면 아래와 같다.
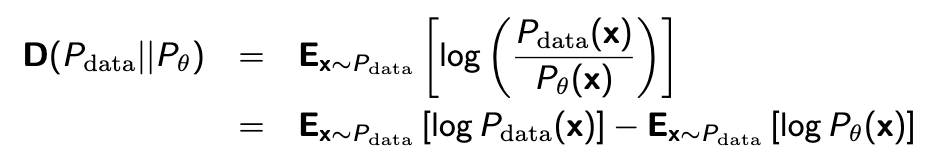
우리가 구해야 하는건 \( \theta \) 인데 여기서 첫번째 term은 \( P_\theta \) 관련이 없으니까 빼면 아래와 같은 식으로 요약된다.

즉 \( P_\text{data} \)에서 sampling된 sample들 x (우리가 가지고 있는 데이터셋 \( D \) 에 있는 sample들 ) 에 대해서 \( P_\theta \)의 log-likelihood를 최대화 하면 된다. 식을 정리하면 아래와 같아진다.

이제 \( P_\theta \) 모델이 이전에 얘기한 autoregressive 모델이라고 가정하고 maximum likelihood를 구하는 과정을 보자.

최종 목표는 위의 L 값을 최대화 하는것이 되는것이고 Gradient Descent 방식으로 \( \theta \) 값을 최적화 해나가면 된다. 보통 L에 log를 씌워서 log L 값을 계산하고 아래방식으로 계산한다.

여기서 데이터셋인 D가 커져서 데이터 갯수인 m 이 매우 커지면 계산이 힘들어진다. 아래 처럼 따라서 Monte Carlo 방식으로 데이터셋 D에서 일부 x로 sample을 얻어 이에 대한 gradient를 계산해서 Stochastic Gradient Descent 방식으로 적용하게 된다.

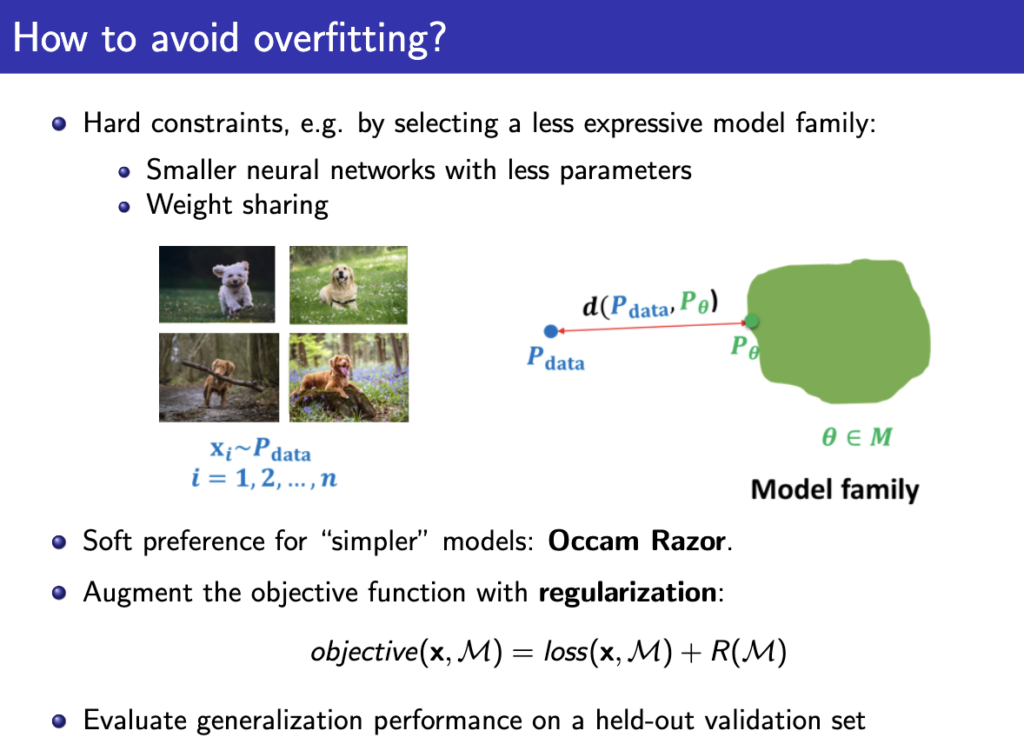
이렇게 학습된 모델에는 overfitting될 위험이 항상 존재한다. 쉽게 예를들면 데이터셋에 있는 sample x에 대해서는 확률 1로 예측해버리고 데이터셋에 없는 sample은 그냥 확률 0이 되버리는 케이스를 생각할 수 있다. 즉 model이 dataset D 그 자체가 되어버리는건데 분명 원래 확률분포 \( P_\text{data} \) 는 그렇게 극단적으로 생겼을리가 없다. 대충 비슷한 이미지면 높은 확률이 나와야하는데 좀만 달라도 극단적으로 값이 바뀌는 이런 overfitting은 좋지 않다. 이를 위해 우리가 찾는 분포의 hypothesis space에 약간의 제약을 가한다. 쉽게 얘기하면 모델의 파라미터수를 키우고 복잡하게 만들면 복잡한 hypothesis space 라는 가정인거고 모델을 단순히, 극단적으로 linear 모델로 만들면 hypothesis space가 직선이라는 얘기이다. 따라서 모델을 단순히 만드냐, 복잡하게 만드냐에 의해 차이가 생기고 이때 Bias-Variance trade off가 발생한다. 딥러닝에선 항상 발생하는 아래와같은 이슈이다.

이런 overfitting을 막기위해 학습시킬때 최대한 간단한 모델을 쓰려고 하고 regularization 방법등을 적용한다.
마지막으로는 Conditional generative model인데 그냥 모델이 condition으로 다른 modality나 데이터를 받아서 생성을 하게 되는거고 conditional 생성에만 집중하면 되고 joint distribution을 구할 필요는 없다는게 끝이다.

답글 남기기
댓글을 달기 위해서는 로그인해야합니다.